
Python 第2页
世界上最好的编程语言(
排序
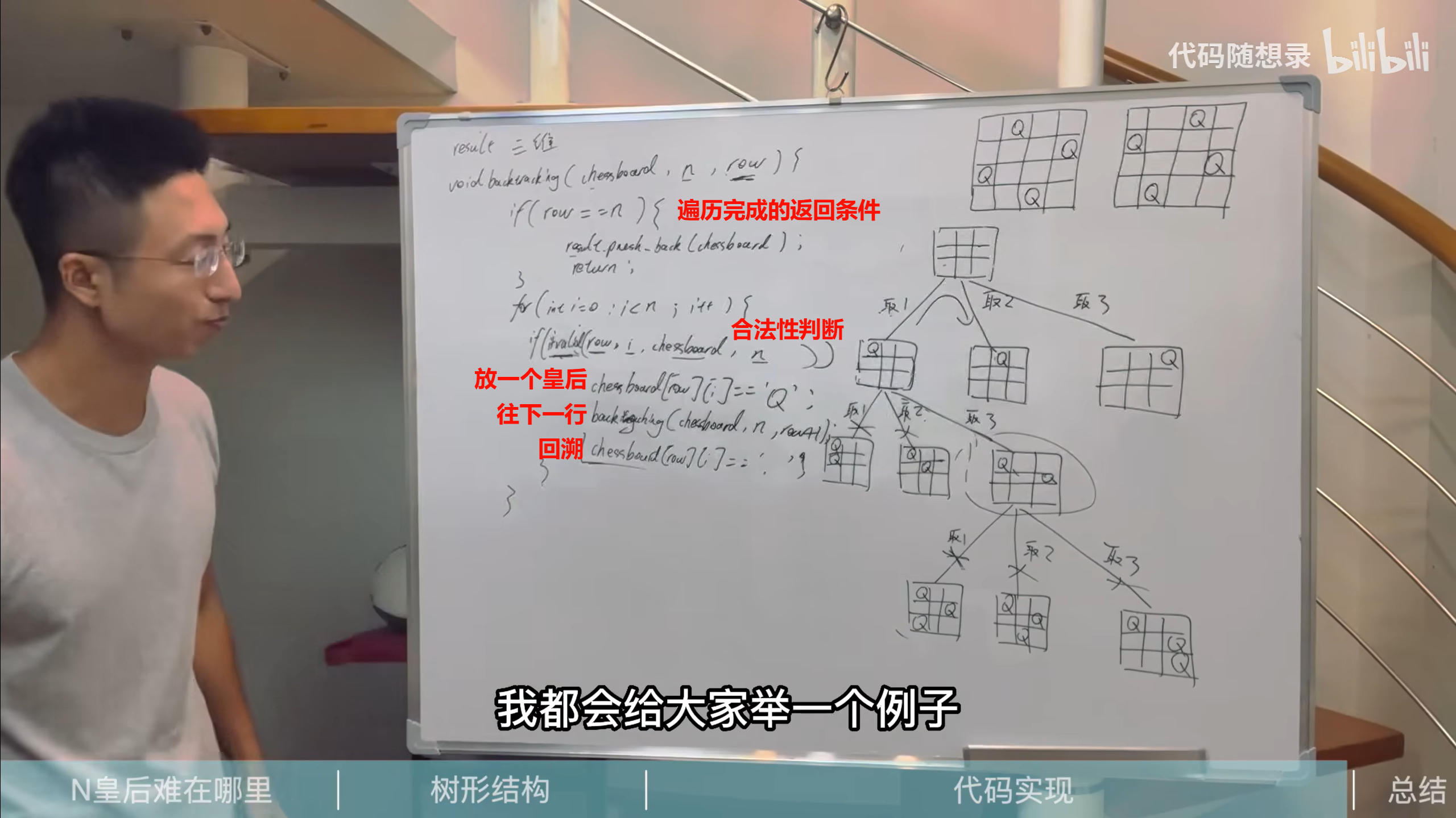
【算法】【Python】N皇后问题的三种解法
本文分析了N皇后问题的三种解法:回溯法通过逐行尝试并安全检测实现,时间复杂度O(n!)但实现简单;分支限界法利用列和对角线标记数组将安全判断优化至O(1),通过空间换时间显著提升速度;位运算...

【算法】【Python】蓝桥杯Python组比赛技巧
本文介绍了Python在蓝桥杯比赛中的常用技巧,包括序列翻转、数字进制转换、数学表达式解析、自定义排序、遍历序列、数据结构操作、组合与排列生成、双端队列、阶乘计算、日期处理、字符计数、有...

【人工智能】【Python】离线环境下huggingface预训练权重导入流程
我分享了在离线环境下导入Hugging Face预训练权重的解决方案。当因网络问题无法自动下载时,我会先在有网络的设备上定位~/.cache/huggingface/hub缓存目录,将所需的预训练权重文件下载至此。然...
【人工智能】【Python】在Scikit-Learn中使用KNN(K最近邻算法)
在Scikit-Learn中使用KNN(K最近邻算法),代码体现了机器学习项目的典型工作流:数据准备→特征工程→模型训练→参数调优→性能评估。特别值得注意的是对数据分布保持(stratify)、特征标准化...
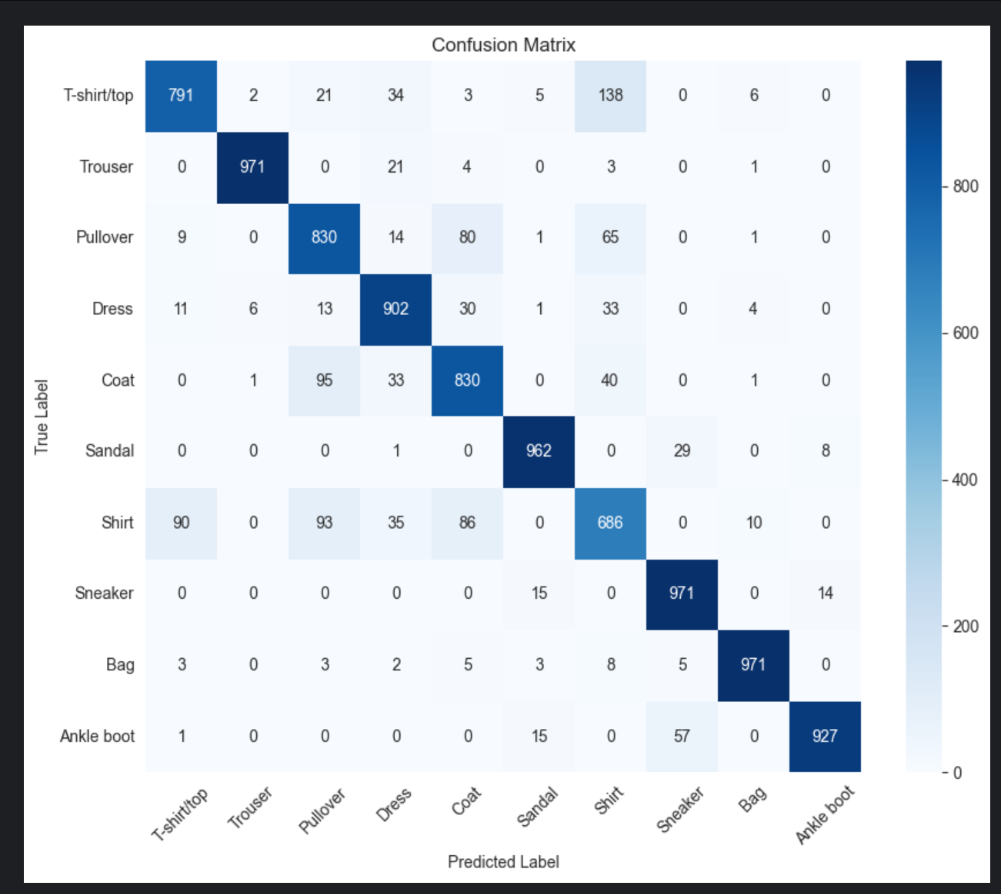
【人工智能】【Python】多层感知机应用实验
我进行了一次多层感知机(MLP)的应用实验。我使用PyTorch构建了一个含隐藏层、ReLU激活和Dropout的MLP模型,在Fashion-MNIST数据集上进行服装图像分类。通过在GPU上训练,我探索了不同训练轮数...
【Python】第四次实验
我完成了10个Python面向对象编程实验,涵盖了类定义、继承、多态、魔术方法等核心概念。主要内容包括:实现自动编号的学生类、几何计算工具类、带属性验证的矩形类、3D向量运算类、家具管理系统...






