

实验 1:基于 RNN、LSTM 的图片分类任务
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, classification_report
import numpy as np
# 设置matplotlib中文字体和清晰度
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["font.size"] = 10
# 设置随机种子保证可复现性
torch.manual_seed(42)
np.random.seed(42)
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 数据准备
# MNIST图像resize到32x32,转换为tensor然后再归一化
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST的均值和标准差
])
# 加载数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 划分训练集和验证集 (80%训练,20%验证)
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
# 数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
print(f"训练集大小: {len(train_dataset)}")
print(f"验证集大小: {len(val_dataset)}")
print(f"测试集大小: {len(test_dataset)}")
# 模型构建
# 基于RNN的图像分类器
class RNNClassifier(nn.Module):
def __init__(self, input_size=32, hidden_size=128, num_layers=2, num_classes=10):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# RNN层: input_size是每行的像素数(32)
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=0.3 if num_layers > 1 else 0
)
# 全连接层用于分类
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# x shape: (batch, 1, 32, 32)
batch_size = x.size(0)
# 将图像reshape为序列: (batch, seq_len=32, input_size=32)
x = x.view(batch_size, 32, 32)
# RNN前向传播
# out shape: (batch, seq_len, hidden_size)
out, hidden = self.rnn(x)
# 取最后一个时间步的输出
out = out[:, -1, :] # (batch, hidden_size)
# 通过全连接层得到分类结果
out = self.fc(out) # (batch, num_classes)
return out
# 基于LSTM的图像分类器
class LSTMClassifier(nn.Module):
def __init__(self, input_size=32, hidden_size=128, num_layers=2, num_classes=10):
super(LSTMClassifier, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# LSTM层
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=0.3 if num_layers > 1 else 0
)
# 全连接层
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
batch_size = x.size(0)
x = x.view(batch_size, 32, 32)
# LSTM前向传播
out, (hidden, cell) = self.lstm(x)
# 取最后一个时间步的输出
out = out[:, -1, :]
# 分类
out = self.fc(out)
return out
# LeNet-5卷积神经网络
class LeNet(nn.Module):
def __init__(self, num_classes=10):
super(LeNet, self).__init__()
# 卷积层1: 1 -> 6 channels
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 32 -> 16
# 卷积层2: 6 -> 16 channels
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 12 -> 6
# 全连接层
self.fc1 = nn.Linear(16 * 6 * 6, 120)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(120, 84)
self.relu4 = nn.ReLU()
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
# 卷积层1
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
# 卷积层2
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
# 展平
x = x.view(x.size(0), -1)
# 全连接层
x = self.fc1(x)
x = self.relu3(x)
x = self.fc2(x)
x = self.relu4(x)
x = self.fc3(x)
return x
# 训练和评估
def train_epoch(model, train_loader, criterion, optimizer, device):
"""训练一个epoch"""
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / total
epoch_acc = 100 * correct / total
return epoch_loss, epoch_acc
def validate(model, val_loader, criterion, device):
"""在验证集上评估"""
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
epoch_loss = running_loss / total
epoch_acc = 100 * correct / total
return epoch_loss, epoch_acc
# 完整的训练流程
def train_model(model, model_name, train_loader, val_loader, num_epochs=20, lr=0.001):
print(f"\n{'=' * 50}")
print(f"训练模型: {model_name}")
print(f"{'=' * 50}")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 记录训练历史
history = {
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
best_val_acc = 0.0
for epoch in range(num_epochs):
# 训练
train_loss, train_acc = train_epoch(model, train_loader, criterion, optimizer, device)
# 验证
val_loss, val_acc = validate(model, val_loader, criterion, device)
# 记录
history['train_loss'].append(train_loss)
history['train_acc'].append(train_acc)
history['val_loss'].append(val_loss)
history['val_acc'].append(val_acc)
# 保存最佳模型
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), f'{model_name}_best.pth')
# 打印进度
print(f'Epoch [{epoch + 1}/{num_epochs}] | '
f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}% | '
f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')
print(f"\n{model_name} 最佳验证准确率: {best_val_acc:.2f}%")
# 加载最佳模型
model.load_state_dict(torch.load(f'{model_name}_best.pth'))
return model, history
# 对比实验
# 测试流程
def evaluate_model(model, test_loader, device):
model.eval()
all_preds = []
all_labels = []
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return accuracy, np.array(all_preds), np.array(all_labels)
# 绘制训练曲线
def plot_training_curves(histories, model_names):
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 训练损失
ax = axes[0, 0]
for history, name in zip(histories, model_names):
ax.plot(history['train_loss'], label=name)
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.set_title('Training Loss')
ax.legend()
ax.grid(True, alpha=0.3)
# 验证损失
ax = axes[0, 1]
for history, name in zip(histories, model_names):
ax.plot(history['val_loss'], label=name)
ax.set_xlabel('Epoch')
ax.set_ylabel('Loss')
ax.set_title('Validation Loss')
ax.legend()
ax.grid(True, alpha=0.3)
# 训练准确率
ax = axes[1, 0]
for history, name in zip(histories, model_names):
ax.plot(history['train_acc'], label=name)
ax.set_xlabel('Epoch')
ax.set_ylabel('Accuracy (%)')
ax.set_title('Training Accuracy')
ax.legend()
ax.grid(True, alpha=0.3)
# 验证准确率
ax = axes[1, 1]
for history, name in zip(histories, model_names):
ax.plot(history['val_acc'], label=name)
ax.set_xlabel('Epoch')
ax.set_ylabel('Accuracy (%)')
ax.set_title('Validation Accuracy')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(f'training_curves_{model_names}.png', dpi=300, bbox_inches='tight')
print("训练曲线已保存")
plt.show()
# 绘制混淆矩阵
def plot_confusion_matrices(all_preds, all_labels, model_names):
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
for ax, preds, labels, name in zip(axes, all_preds, all_labels, model_names):
cm = confusion_matrix(labels, preds)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', ax=ax, cbar=False)
ax.set_xlabel('Predicted')
ax.set_ylabel('True')
ax.set_title(f'{name} - Confusion Matrix')
plt.tight_layout()
plt.savefig(f'confusion_matrices_{model_names}.png', dpi=300, bbox_inches='tight')
print("混淆矩阵已保存")
plt.show()
# 打印对比分析报告
def print_comparison_report(accuracies, all_preds, all_labels, model_names):
print("\n" + "=" * 70)
print("模型对比分析报告")
print("=" * 70)
# 测试准确率对比
print("\n1. 测试集准确率对比:")
print("-" * 50)
for name, acc in zip(model_names, accuracies):
print(f" {name:15s}: {acc:.2f}%")
# 分类报告
print("\n2. 详细分类报告:")
print("-" * 50)
for name, preds, labels in zip(model_names, all_preds, all_labels):
print(f"\n{name}:")
print(classification_report(labels, preds, digits=4))
# 性能分析
print("\n3. 性能分析:")
print("-" * 50)
best_idx = np.argmax(accuracies)
print(f" 最佳模型: {model_names[best_idx]} (准确率: {accuracies[best_idx]:.2f}%)")
if __name__ == "__main__":
# 生成模型类的对象
rnn_model = RNNClassifier(input_size=32, hidden_size=128, num_layers=2)
lstm_model = LSTMClassifier(input_size=32, hidden_size=128, num_layers=2)
cnn_model = LeNet(num_classes=10)
# 训练所有模型
models = [rnn_model, lstm_model, cnn_model]
model_names = ['RNN', 'LSTM', 'LeNet']
histories = []
for model, name in zip(models, model_names):
trained_model, history = train_model(
model, name, train_loader, val_loader,
num_epochs=20, lr=0.001
)
histories.append(history)
# 绘制训练曲线
plot_training_curves(histories, model_names)
# 在测试集上评估
print("\n" + "=" * 70)
print("测试集评估")
print("=" * 70)
accuracies = []
all_preds = []
all_labels = []
for model, name in zip(models, model_names):
model.load_state_dict(torch.load(f'{name}_best.pth'))
acc, preds, labels = evaluate_model(model, test_loader, device)
accuracies.append(acc)
all_preds.append(preds)
all_labels.append(labels)
print(f"{name} 测试准确率: {acc:.2f}%")
# 绘制混淆矩阵
plot_confusion_matrices(all_preds, all_labels, model_names)
# 打印对比分析报告
print_comparison_report(accuracies, all_preds, all_labels, model_names)1.数据准备
# 加载数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 划分训练集和验证集 (80%训练,20%验证)
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])从PyTorch加载MINIST数据集,训练验证划分比例为4:1
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # MNIST的均值和标准差
])每一张图片会resize到32×32

2.模型构建(RNN、LSTM:定义输入 / 隐藏层维度等,结合全连接层分类)
# 模型构建
# 基于RNN的图像分类器
class RNNClassifier(nn.Module):
def __init__(self, input_size=32, hidden_size=128, num_layers=2, num_classes=10):
super(RNNClassifier, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# RNN层: input_size是每行的像素数(32)
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=0.3 if num_layers > 1 else 0
)
# 全连接层用于分类
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# x shape: (batch, 1, 32, 32)
batch_size = x.size(0)
# 将图像reshape为序列: (batch, seq_len=32, input_size=32)
x = x.view(batch_size, 32, 32)
# RNN前向传播
# out shape: (batch, seq_len, hidden_size)
out, hidden = self.rnn(x)
# 取最后一个时间步的输出
out = out[:, -1, :] # (batch, hidden_size)
# 通过全连接层得到分类结果
out = self.fc(out) # (batch, num_classes)
return out
# 基于LSTM的图像分类器
class LSTMClassifier(nn.Module):
def __init__(self, input_size=32, hidden_size=128, num_layers=2, num_classes=10):
super(LSTMClassifier, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# LSTM层
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=0.3 if num_layers > 1 else 0
)
# 全连接层
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
batch_size = x.size(0)
x = x.view(batch_size, 32, 32)
# LSTM前向传播
out, (hidden, cell) = self.lstm(x)
# 取最后一个时间步的输出
out = out[:, -1, :]
# 分类
out = self.fc(out)
return out3.模型训练(记录损失、准确率及训练曲线)
4.与传统 CNN 对比(CNN 模型构建、训练及验证评估)
# LeNet-5卷积神经网络
class LeNet(nn.Module):
def __init__(self, num_classes=10):
super(LeNet, self).__init__()
# 卷积层1: 1 -> 6 channels
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # 32 -> 16
# 卷积层2: 6 -> 16 channels
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2) # 12 -> 6
# 全连接层
self.fc1 = nn.Linear(16 * 6 * 6, 120)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(120, 84)
self.relu4 = nn.ReLU()
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
# 卷积层1
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
# 卷积层2
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
# 展平
x = x.view(x.size(0), -1)
# 全连接层
x = self.fc1(x)
x = self.relu3(x)
x = self.fc2(x)
x = self.relu4(x)
x = self.fc3(x)
return x
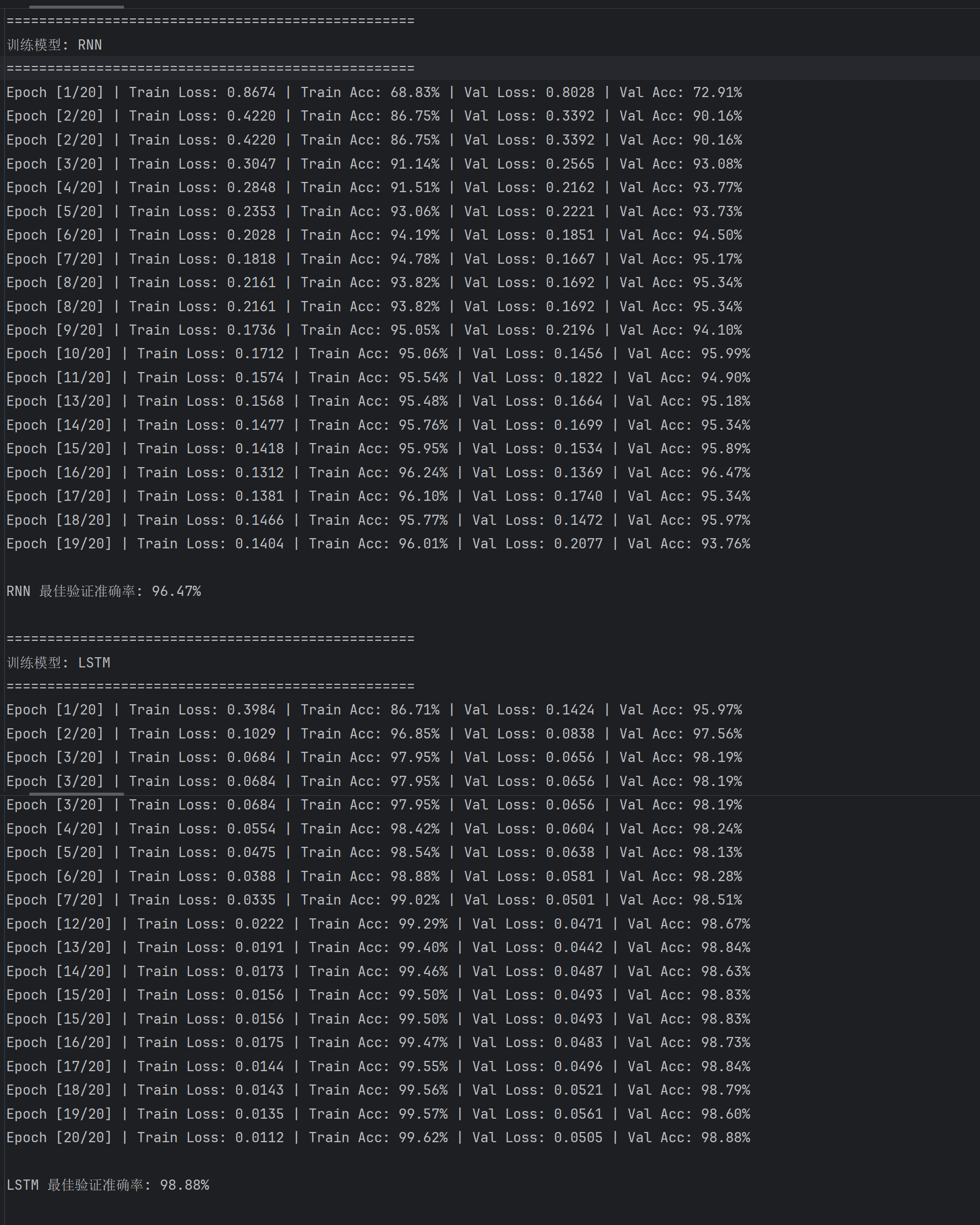
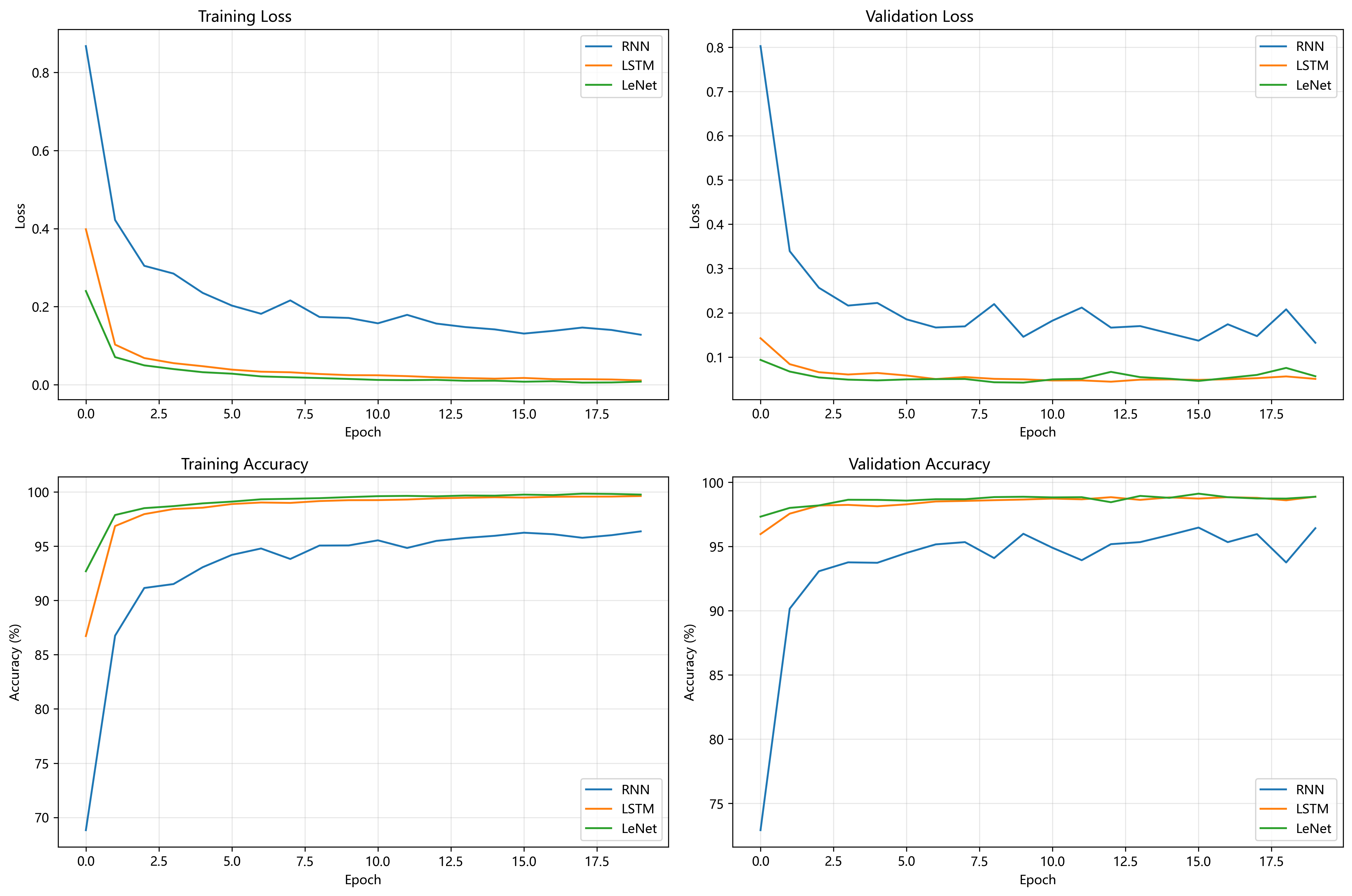
结合第3和第4小节,从训练与验证曲线看,LeNet 在训练损失下降最快且最终最低,训练与验证准确率均快速趋近 100% 且稳定;LSTM 训练损失下降和准确率提升速度优于 RNN,验证阶段更平稳;RNN 训练损失下降慢、波动大,准确率提升滞后,验证阶段也波动明显。LeNet 凭借卷积对图像特征的高效提取,训练收敛最优;LSTM 以门控机制缓解 RNN 梯度消失,在序列特征捕捉上更稳定;RNN 因梯度消失问题,训练过程低效、泛化性弱,最终测试表现最差 。整体体现出卷积网络对图像任务的适配性,及 LSTM 相对基础 RNN 的结构优势。
5.对比实验(测试集性能评估,混淆矩阵、分类报告等对比分析)
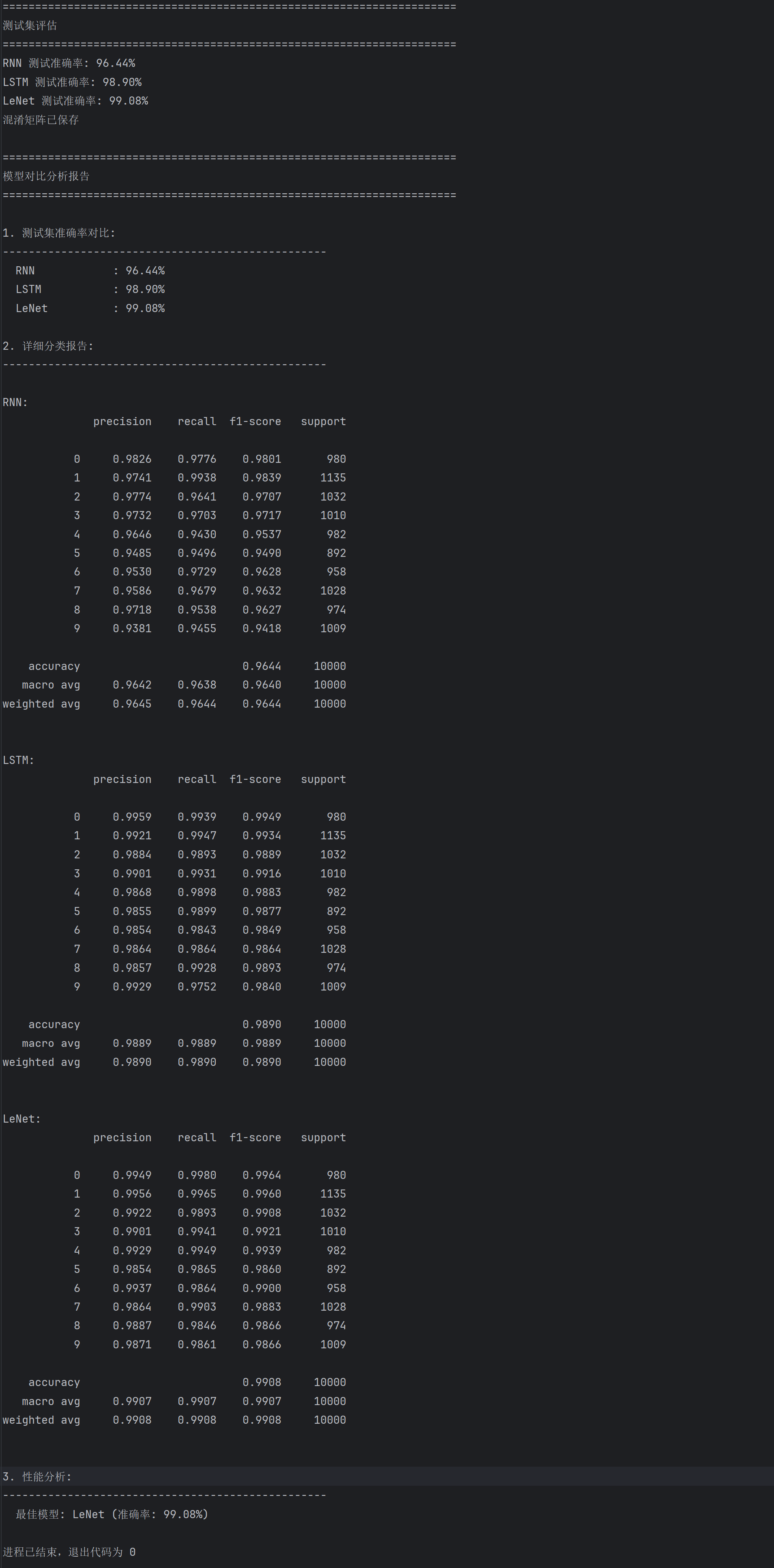
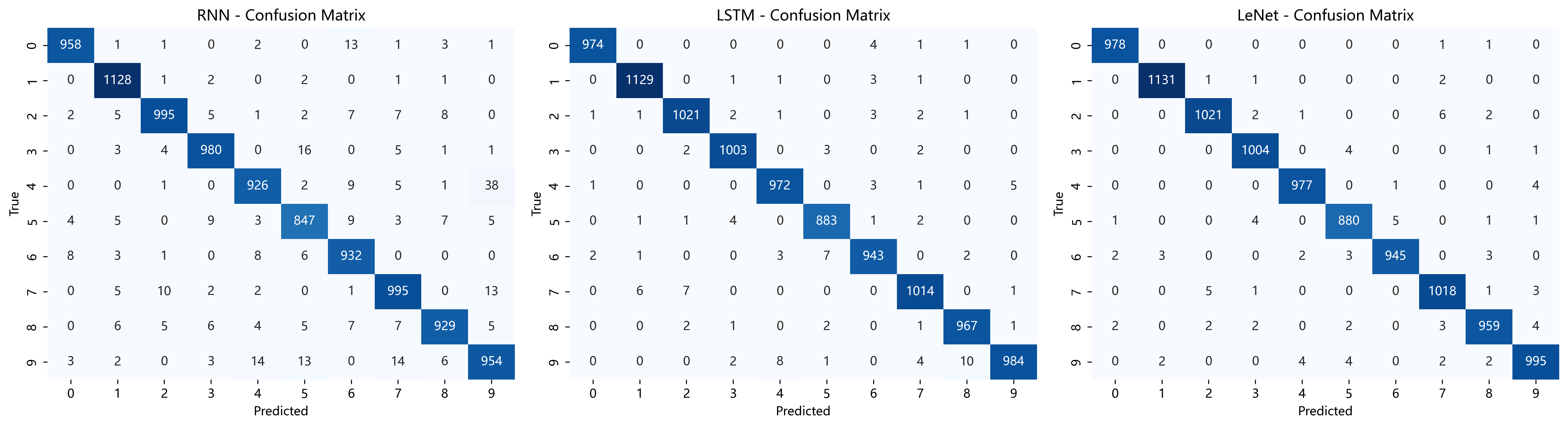
如上图日志和混淆矩阵可以看出,LeNet 测试准确率达 99.08%,表现最优;LSTM 为 98.90%,优于 RNN 的 96.44% 。从混淆矩阵看,RNN 错误更分散(如数字 4、9 等类别间混淆较明显),LSTM 错误更少,LeNet 对角线(正确分类)更集中 。这一结果体现出,卷积网络 LeNet 对图像特征提取更高效,LSTM 因缓解梯度消失、更好捕捉序列关联,性能优于基础 RNN ,反映出不同网络结构对图像分类任务的适配性差异。
实验 2:基于 RNN、LSTM 的文本分类任务
1.文本数据预处理与嵌入(数据准备、分词、词汇表构建、词向量嵌入)
# Step 1: 文本数据预处理与嵌入
print("Loading IMDb dataset...")
dataset = load_dataset("imdb")
train_data = dataset["train"]
test_data = dataset["test"]
# 文本预处理函数
def preprocess_text(text):
# 简单的文本清理
text = text.lower()
text = re.sub(r'[^\w\s]', '', text) # 移除标点符号
text = re.sub(r'\s+', ' ', text).strip() # 标准化空白
return text
# 构建词汇表
def build_vocab(texts, min_freq=10):
word_counts = Counter()
for text in texts:
words = preprocess_text(text).split()
word_counts.update(words)
# 过滤低频词
vocab = {'<pad>': 0, '<unk>': 1}
idx = 2
for word, count in word_counts.items():
if count >= min_freq:
vocab[word] = idx
idx += 1
return vocab
# 构建词汇表
print("Building vocabulary...")
train_texts = [example['text'] for example in train_data]
vocab = build_vocab(train_texts)
print(f"Vocabulary size: {len(vocab)}")
# 文本转换为数值编码
def text_to_indices(text, vocab, max_len=500):
words = preprocess_text(text).split()
indices = [vocab.get(word, vocab['<unk>']) for word in words[:max_len]]
# 填充序列
if len(indices) < max_len:
indices = indices + [vocab['<pad>']] * (max_len - len(indices))
return indices
# 自定义数据集类
class IMDbDataset(Dataset):
def __init__(self, data, vocab, max_len=500):
self.data = data
self.vocab = vocab
self.max_len = max_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
text = self.data[idx]['text']
label = self.data[idx]['label'] # 0: negative, 1: positive
# 转换文本为索引序列
indices = text_to_indices(text, self.vocab, self.max_len)
return torch.tensor(indices), torch.tensor(label)
# 创建DataLoader
print("Creating data loaders...")
batch_size = 64
max_seq_len = 500
train_dataset = IMDbDataset(train_data, vocab, max_seq_len)
test_dataset = IMDbDataset(test_data, vocab, max_seq_len)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)数据集是调用HuggingFace的datasets库导入的

2.构建LSTM和RNN网络模型
# Step 2: 构建LSTM网络模型
class LSTMClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim,
n_layers, bidirectional, dropout):
super().__init__()
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=vocab['<pad>'])
# LSTM层
self.lstm = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout if n_layers > 1 else 0,
batch_first=True)
# 全连接层
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
# Dropout层
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text: [batch_size, seq_len]
embedded = self.dropout(self.embedding(text)) # [batch_size, seq_len, embedding_dim]
# LSTM处理
output, (hidden, cell) = self.lstm(embedded)
# 如果是双向LSTM,则合并最后一层的正向和反向隐藏状态
if self.lstm.bidirectional:
hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))
else:
hidden = self.dropout(hidden[-1, :, :])
# 全连接层分类
return self.fc(hidden)
# 构建RNN网络模型
class RNNClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim,
n_layers, bidirectional, dropout):
super().__init__()
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=vocab['<pad>'])
# RNN层
self.rnn = nn.RNN(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout if n_layers > 1 else 0,
batch_first=True)
# 全连接层
self.fc = nn.Linear(hidden_dim * 2 if bidirectional else hidden_dim, output_dim)
# Dropout层
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text: [batch_size, seq_len]
embedded = self.dropout(self.embedding(text)) # [batch_size, seq_len, embedding_dim]
# RNN处理
output, hidden = self.rnn(embedded)
# 双向RNN要合并最后一层的正向和反向隐藏状态
if self.rnn.bidirectional:
hidden = self.dropout(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1))
else:
hidden = self.dropout(hidden[-1, :, :])
# 全连接层分类
return self.fc(hidden)3.模型训练 (配置损失函数、优化器,测试评估)
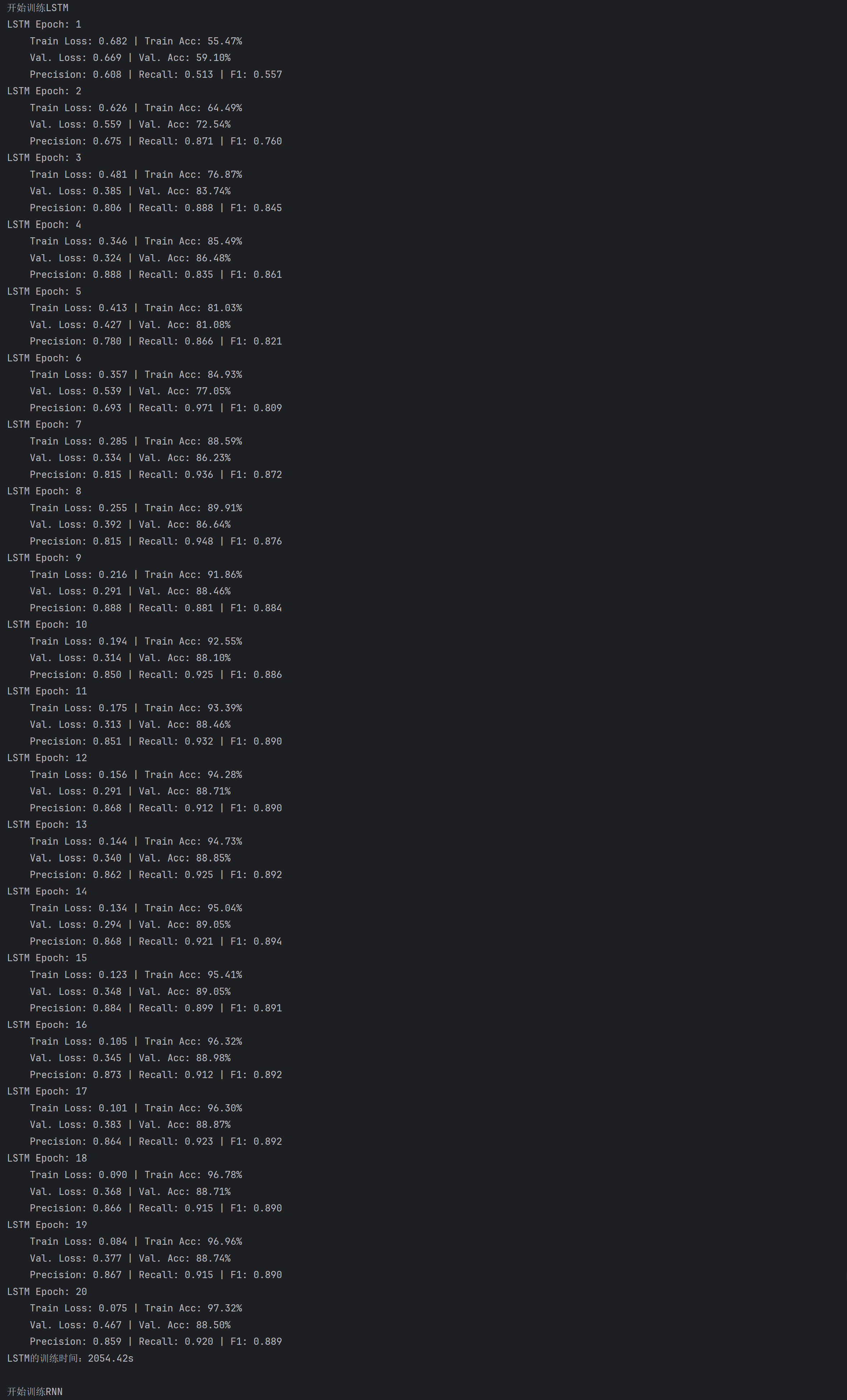
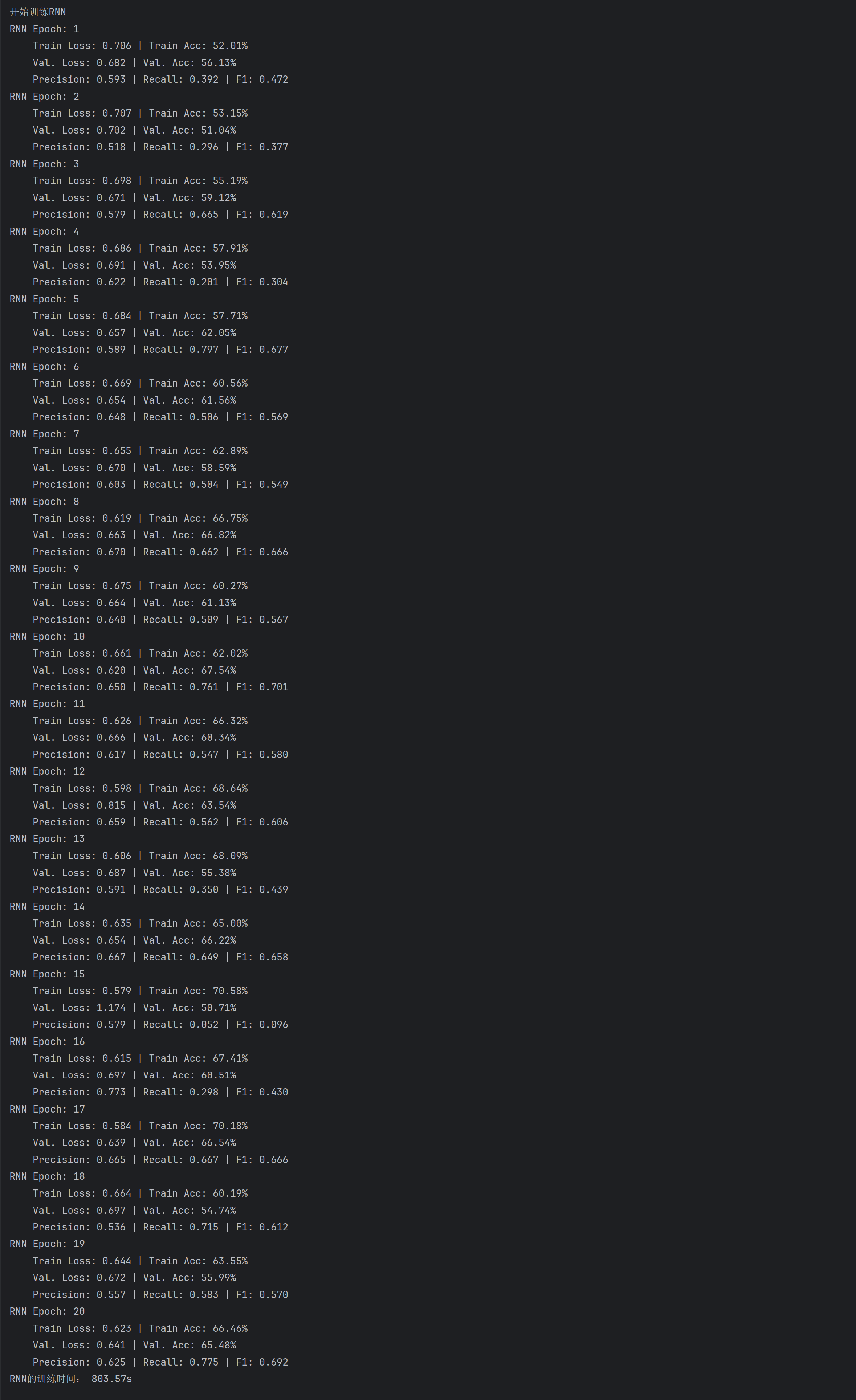
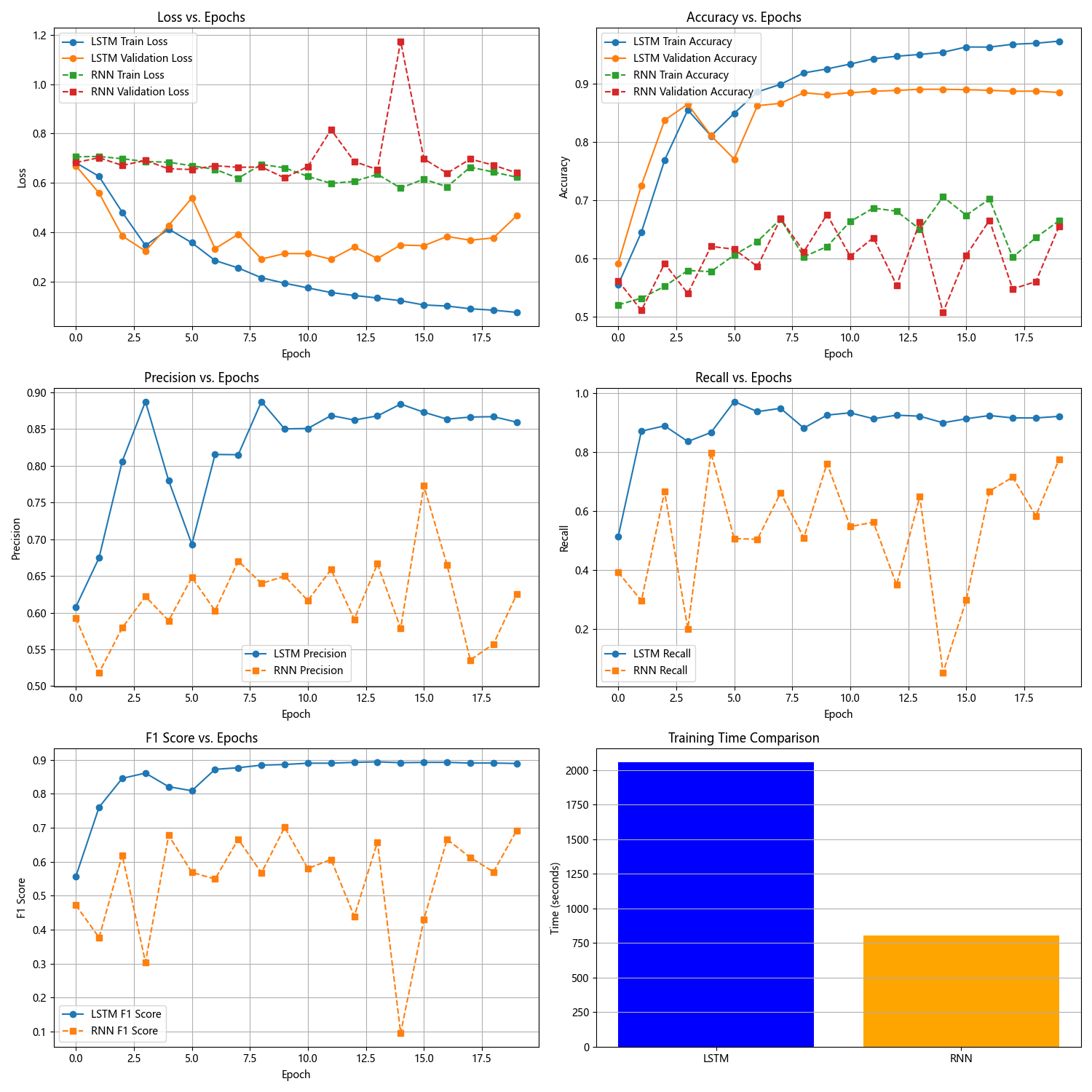
与刚刚MINIST图像分类任务不同的是,从文本分类任务的训练曲线对比来看:LSTM的训练损失持续下降且验证损失稳定,准确率、精确率、召回率及F1分数均稳步提升并维持高位,体现其通过门控机制有效缓解梯度消失,稳定捕捉文本序列依赖的能力。
而RNN各指标(损失、准确率、Precision、Recall、F1)都波动剧烈,验证阶段甚至出现指标骤降,暴露其因梯度消失导致的训练不稳定、泛化能力弱的缺陷。训练时间上,LSTM虽因门控计算更复杂耗时更长,但凭借更高效的序列学习,最终性能远超RNN。
文本分类中,LSTM对RNN结构缺陷的改进,使其更适配序列数据的建模需求,而RNN因核心短板,在训练过程和任务表现上均处于劣势。
4.模型评估与LSTM调优(计算准确率等指标,超参数调优及性能比较)

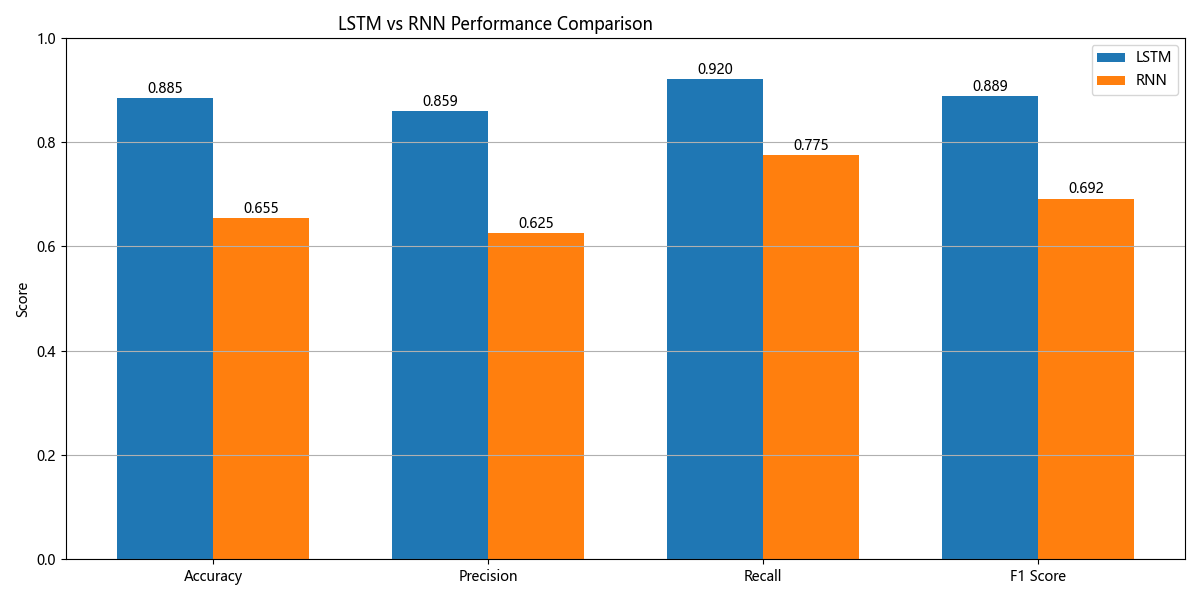
测试集中,LSTM在准确率(0.8850/0.6548,左LSTM/右RNN,下面同理)、精确率(0.8595/0.6249)、召回率(0.9205/0.7746)和F1分数(0.8889/0.6917)上均大幅领先RNN,体现出LSTM通过门控机制缓解梯度消失、更高效捕捉文本序列依赖的结构优势;尽管LSTM训练时间更长(2054.42s/803.57s),但性能提升证明其在文本序列建模中更适配,而RNN因梯度消失导致训练不充分、泛化能力弱,最终测试表现差距显著。
下面是LSTM的调参实验
修改LSTM单元的隐藏状态维度为128(原始256)
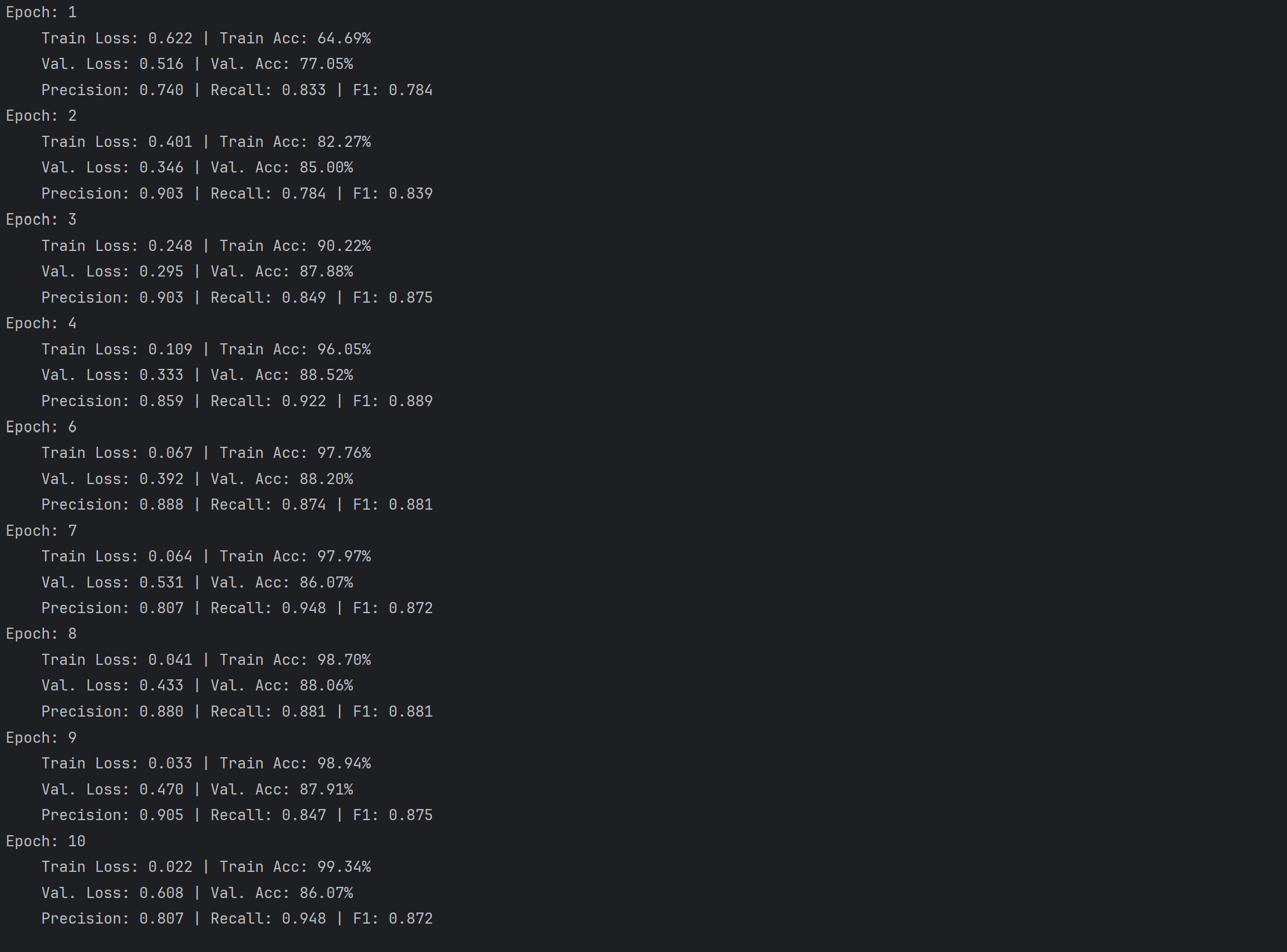
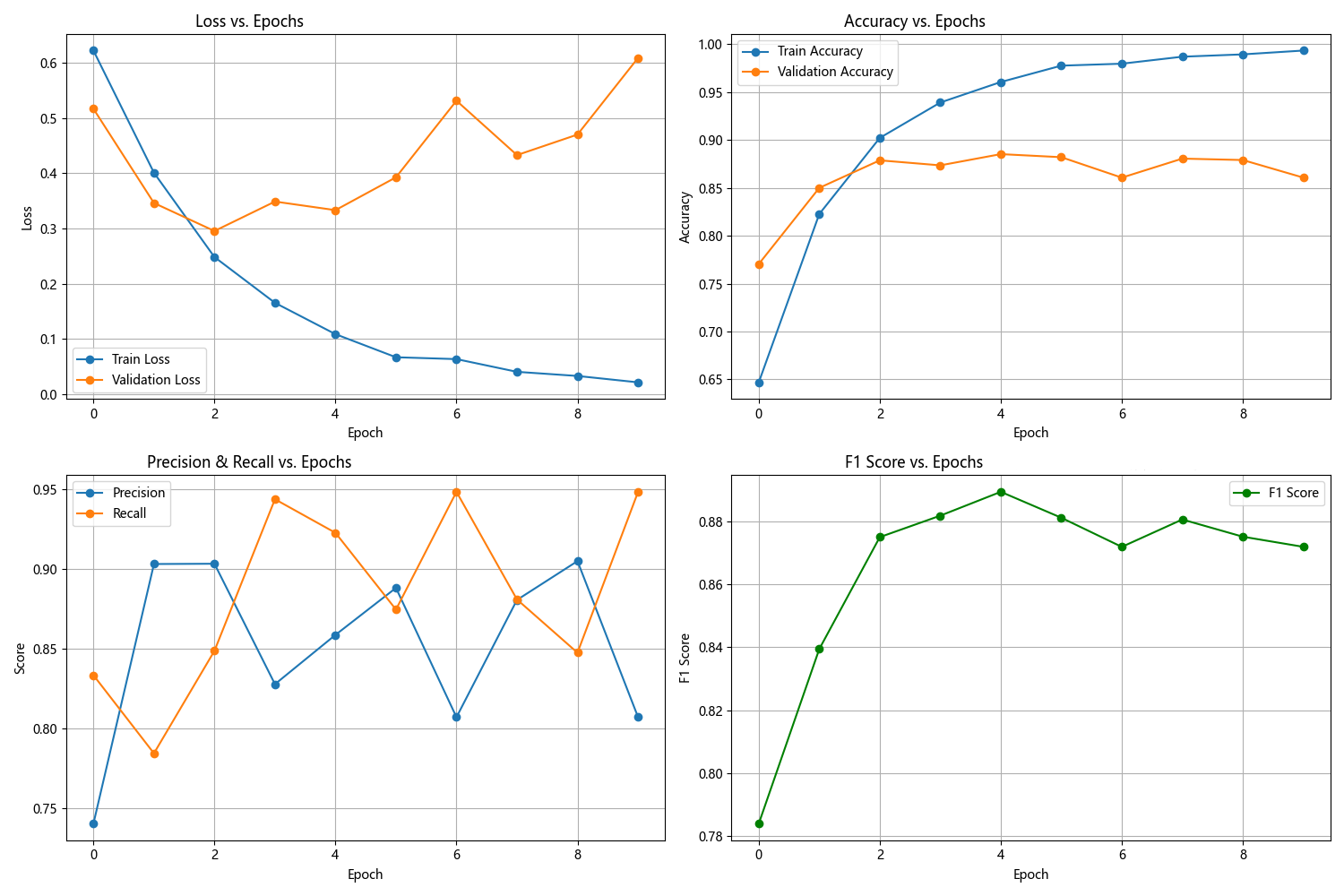
把LSTM隐藏状态维度从256调整为128后,训练阶段的拟合速度有明显提升。初始Epoch的训练损失更低,是0.622,之前为0.682,同时准确率更高,达到64.69%,之前只有55.47%。而且更快突破90%的训练准确率,调整后Epoch2就达到82.27%,原本要到Epoch4才达到85.49%,后期甚至接近100%,Epoch10达到99.34%,这表明模型参数减少后训练效率有所提高。
但是验证集的泛化稳定性却下降了。调整后验证损失波动变得更剧烈,Epoch7验证损失为0.470,到Epoch10就骤升至0.608,验证准确率和F1分数也不断震荡,Epoch2时F1为0.839,Epoch7降至0.875,原始模型的验证指标则更为平稳。这是因为隐藏维度降低,致使模型表达能力受限,128维对复杂文本序列特征的捕捉精度(或者说类似于采样率)会低很多,虽然加速了训练,却难以稳定拟合数据规律,泛化时容易受到干扰。
修改LSTM的堆叠层数为1(原始2)
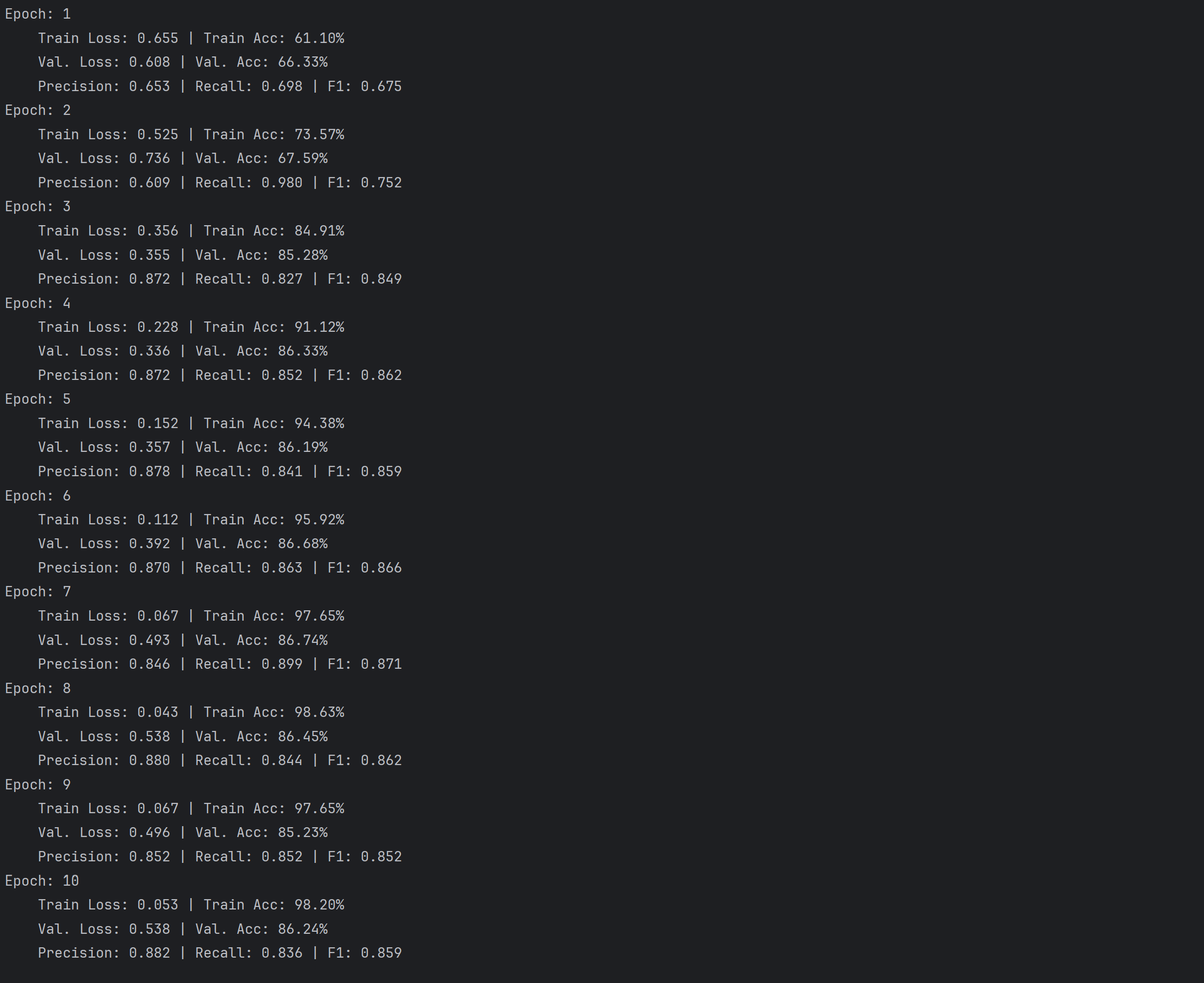
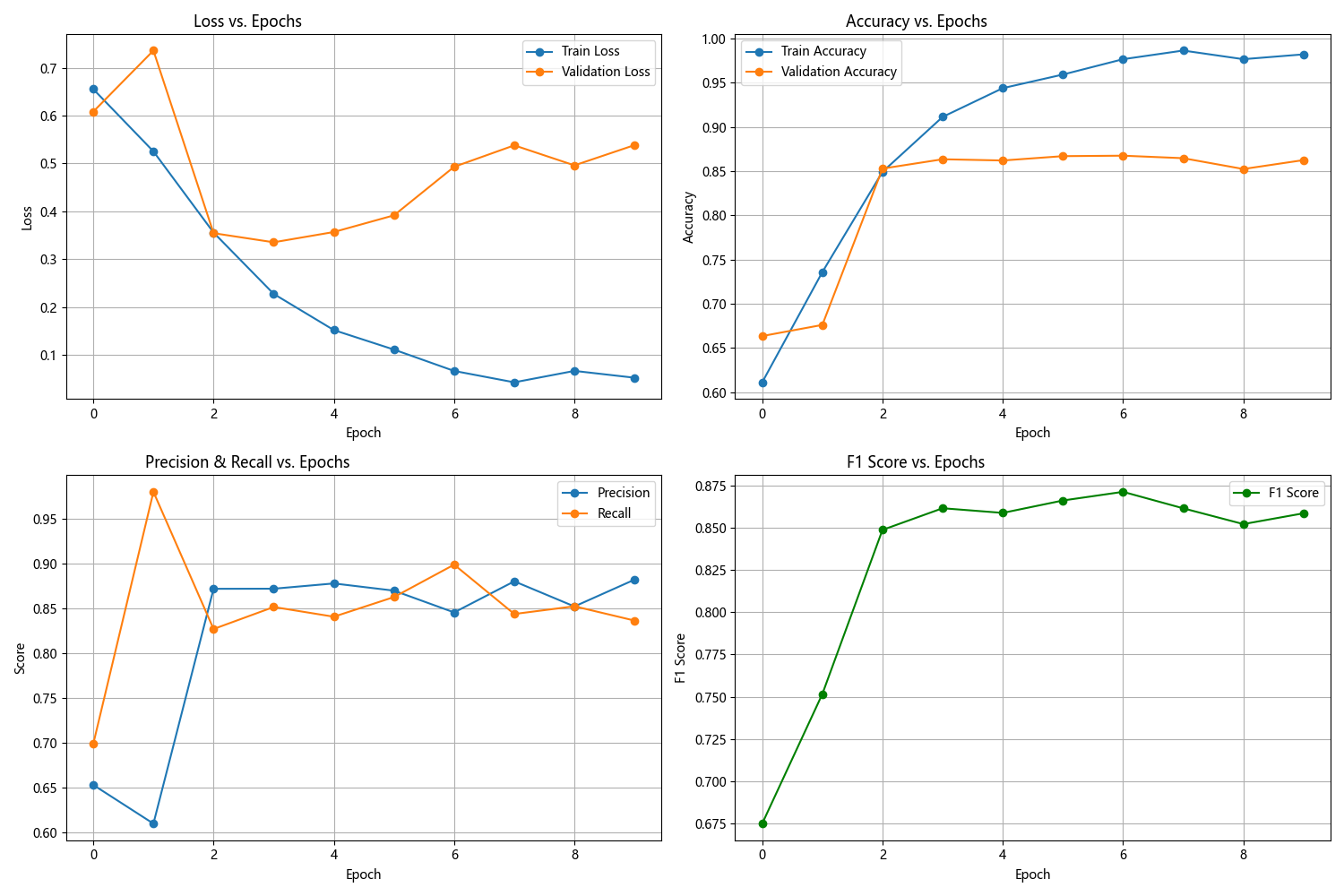
把LSTM堆叠层数从2改成1后,训练初期(例如Epoch1),训练损失变低、准确率变高,拟合速度加快。然而,在验证阶段,损失波动变得更为剧烈,比如Epoch2时验证损失从0.559上升到0.736,各项指标(像准确率、F1等)的稳定性也有所下降。
可能是因为单层LSTM模型复杂度有所降低,虽然能加快初始训练速度,但因为无法深入捕捉文本序列中的多层依赖关系,使得泛化能力有所削弱。与之相比,原始的双层结构借助多层特征的积累,在验证集上表现得更为稳定,最终性能也更好。
将Dropout参数调整为0.1(原始0.5)
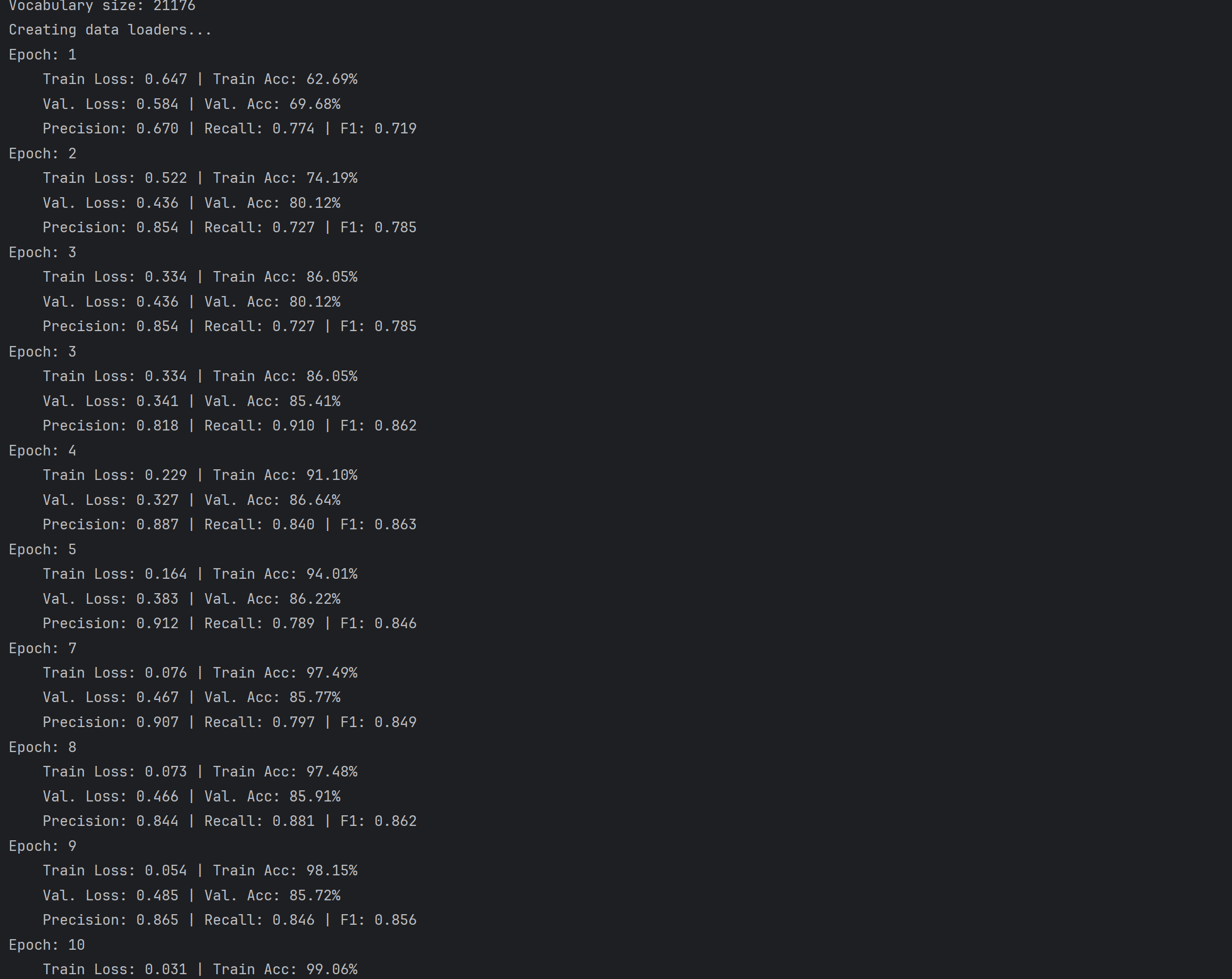
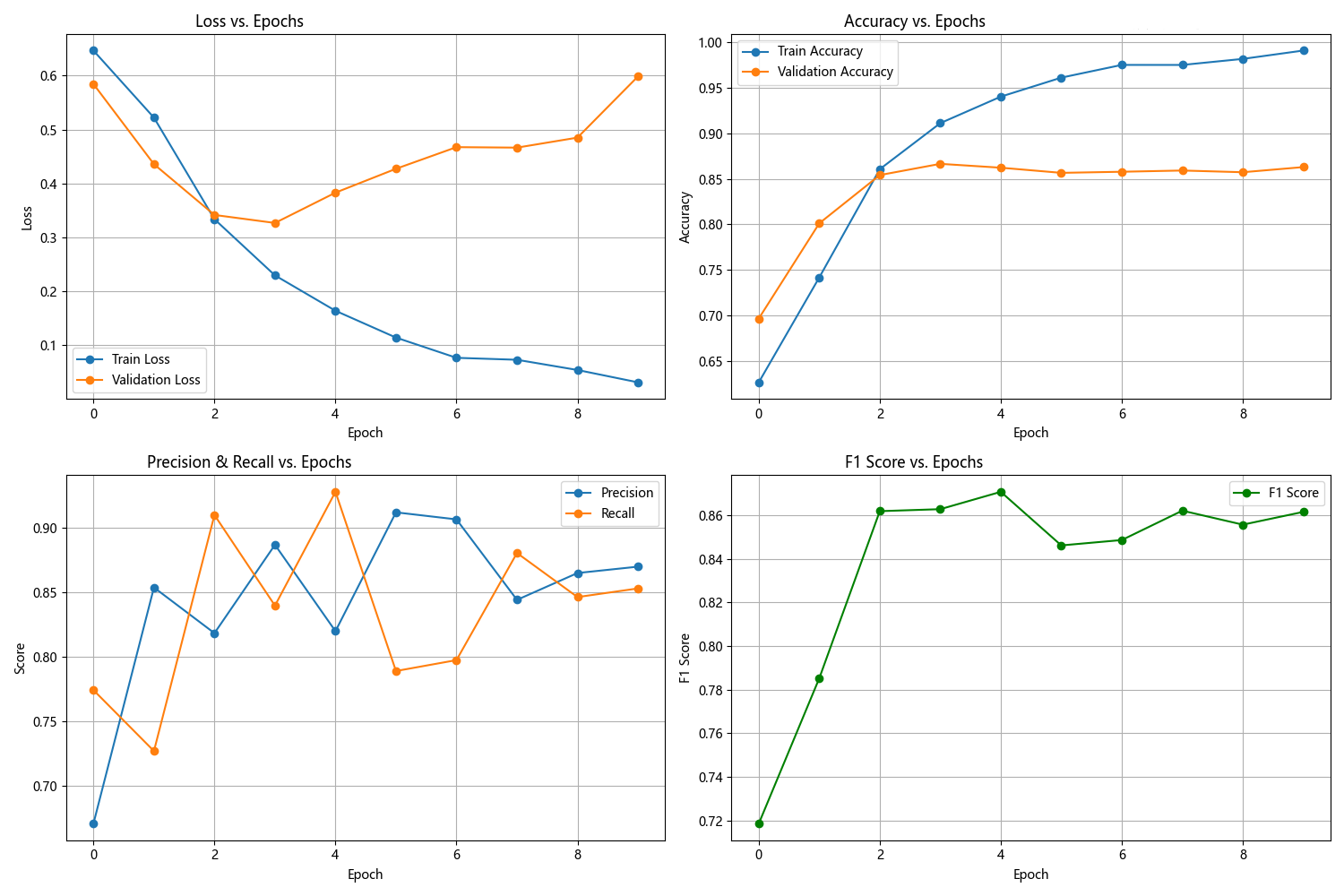
将Dropout从0.5调至0.1后,LSTM训练集拟合速度显著加快,Epoch1训练损失更低、准确率更高,前期验证集指标也更优;但后期训练损失持续下降时,验证损失却上升。Epoch5验证损失0.383、Epoch7达0.467,指标出现下滑,过拟合风险增加。因Dropout减小,模型保留更多神经元,训练时对数据依赖更强,泛化能力减弱。
实验总结
这次试验分为两个任务,在实验1的图片分类任务中,数据准备环节把图像展平成为序列形式进行输入。所搭建的RNN和LSTM运用循环结构对序列特征加以处理,并结合全连接层达成分类目标。在训练进程里,RNN由于梯度消失的缘故,损失降低缓慢,曲线波动较大,与之相比,LSTM依靠门控机制显得更为稳定。然而,二者的表现均不及CNN(像LeNet),这是因为CNN的卷积层在提取图像空间特征方面效率更高。测试集的准确率显示,CNN(也就是LeNet)达到99.08%,明显高于LSTM的98.90%以及RNN的96.44%。混淆矩阵也表明CNN的错误更为集中,这证实了序列模型在非序列数据(图像)上存在适配性方面的局限。
实验2着重于文本分类,先是对文本实施分词、构建词汇表以及词向量嵌入等操作,把文本转变为能够输入的序列数据。在所构建的RNN和LSTM当中,LSTM在训练时更为稳定,损失持续降低,验证指标(准确率、F1等)也更为出色,测试集上的准确率0.8850远远超过RNN的0.6548,这凸显了它在捕捉文本序列依赖方面的优势。超参数调优实验进一步表明,减小dropout(例如从0.5调整到0.1)会加快LSTM的训练拟合速度,但会加剧过拟合现象;降低隐藏维度(比如从256降至128)或者减少堆叠层数(从2层减为1层),虽然能够提升训练速度,却会因模型容量降低致使泛化能力变弱,这意味着LSTM的性能需要在模型复杂度与泛化能力之间寻求平衡。
这让我意识到序列模型的通用性体现在对文本这种序列数据有天然的适配性,而对于图象来说他的效率就不如专门针对图片的CNN模型。在RNN的诸多变体里,LSTM通过门控机制有效地缓解了RNN所面临的梯度消失问题,在捕捉长序列依赖方面更为稳定,这一特性在两项任务中均得到了验证。从基本原理来讲,RNN的循环结构致使它在处理长序列时存在困难,而LSTM的输入门、遗忘门以及输出门能够精准地控制信息流动,这是其具备性能优势的关键所在。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
























暂无评论内容