
Python 第2页
世界上最好的编程语言(
排序
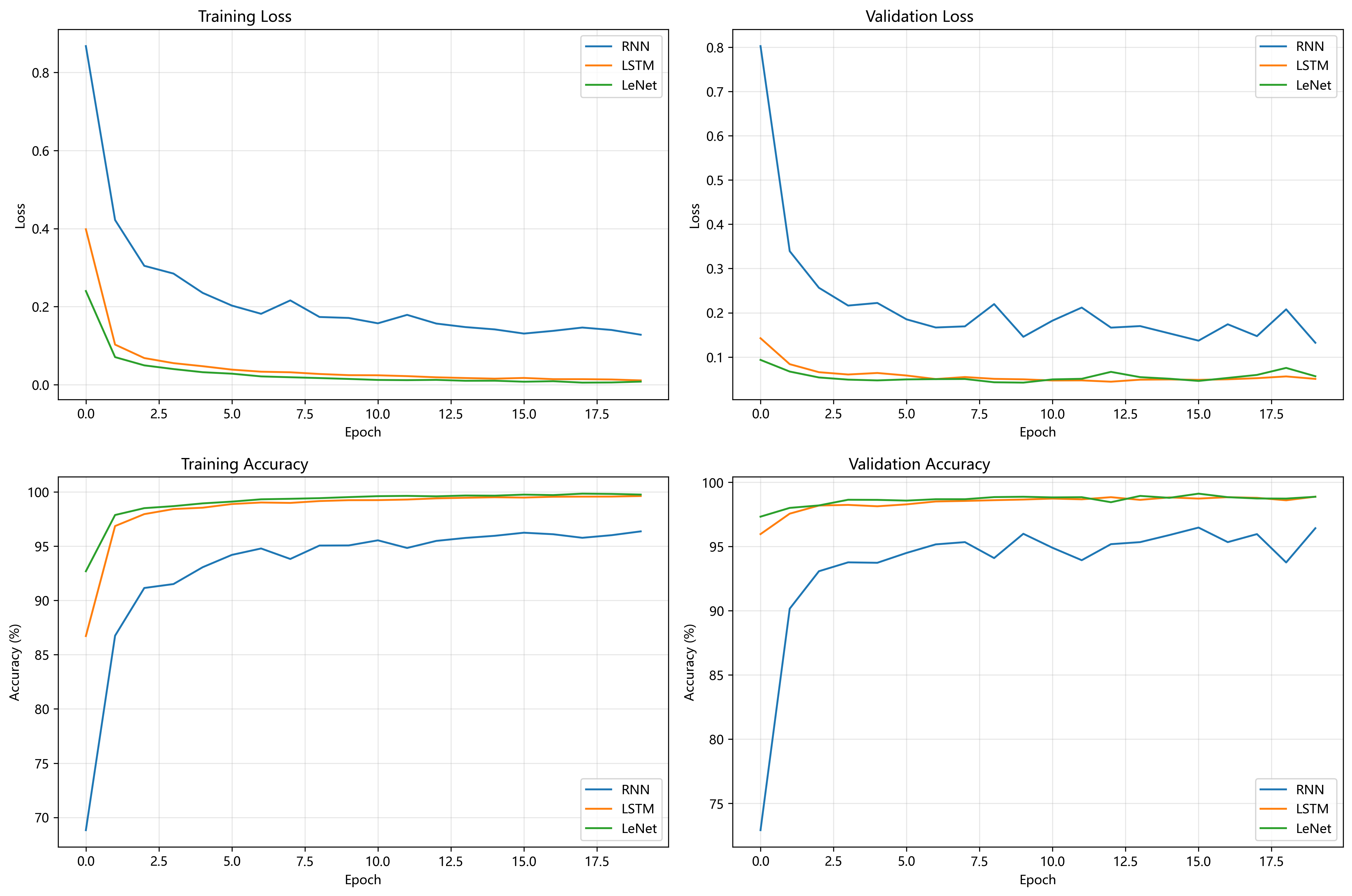
【人工智能】【Python】循环神经网络应用实验
我总结了论文中循环神经网络的应用实验。我通过两个实验对比了RNN和LSTM的性能:实验一是在MNIST图片分类任务中,我将RNN、LSTM与CNN(LeNet)进行比较,发现CNN因其对空间特征提取的优势而表现...

【人工智能】深度学习框架基础操作实验(安装Anaconda、PyCharm、Tensorflow、PyTorch、PaddlePaddle及测试)(重磅!保姆级52张教程图)
我完成了一项深度学习环境搭建与基础操作实验。该实验基于Windows 11系统,使用Anaconda和PyCharm作为基础环境。我分别在独立的虚拟环境中安装了TensorFlow(CPU版)、PaddlePaddle(GPU版)和P...

【DP】使用最小花费爬楼梯
我解决了一道名为“使用最小花费爬楼梯”的算法题。我采用动态规划(DP)方法,定义一个 dp 数组,其中 dp[i] 表示到达第 i 个台阶的最小花费。状态转移方程为:到达当前台阶的最小花费等于当前...
【Python】datetime包
我介绍了 Python 中用于处理日期和时间的内置库 datetime。我讲解了该库中的核心类,包括 datetime(日期时间)、date(日期)、time(时间)和 timedelta(时间差),说明了它们的用途、构造方...
【并查集】Python模板
我提供了一个并查集(Disjoint Set Union)的Python代码模板,用于处理集合的合并与查询问题。我的实现核心是两个函数:findroot和merge。findroot函数用于查找元素的根节点,并通过路径压缩优...
【差分与前缀和】Python模板
我介绍了一种利用差分数组和前缀和技术高效处理区间更新问题的方法。首先,我通过构建差分数组来记录每次区间操作的变化量,即在区间的起始位置加上一个值,在结束位置的后一位减去这个值。然后...






