

人工智能 第7页
倾家荡产买显卡,炼丹科研两不误。数据如海深无底,模型似山高难攀。夜以继日调参数,GPU风扇声声急。精度提升一点点,发际线却步步高。代码千行非一日,实验百次方见真。AI世界多奇妙,科研路上共前行。
排序

【人工智能】用于遥感影像融合的自适应矩形卷积
电子科技大学团队提出自适应矩形卷积(ARConv)解决遥感图像多尺度特征提取难题。针对传统卷积核固定形状与采样点无法适应物体尺寸差异的问题,ARConv通过双子网络动态学习每个像素的卷积核高度...
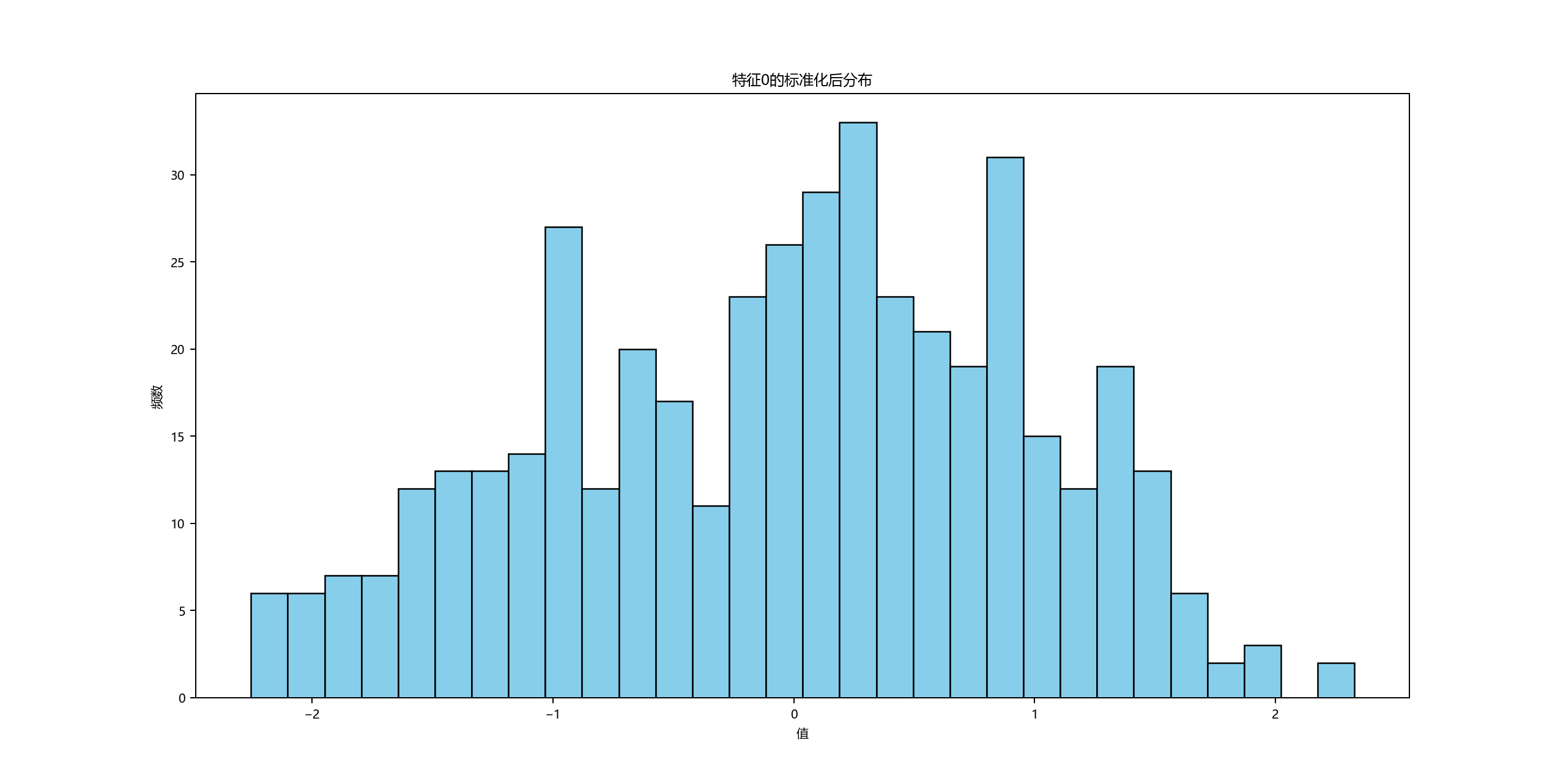
【人工智能】【Python】线性回归算法实验
本实验运用线性回归、岭回归和Lasso回归模型,基于包含442个样本的糖尿病数据集探究正则化方法对模型拟合的影响。通过引入正态分布噪声模拟实际数据特性,使用Z-score标准化后划分训练集/测试集...

【人工智能】无归一化的Transformer
论文作者团队提出用动态双曲正切(DyT)替代Transformer中的归一化层。传统观点认为归一化层(如Layer Norm)对模型稳定性至关重要,但作者发现其核心作用是通过类tanh的非线性压缩极端值。DyT...
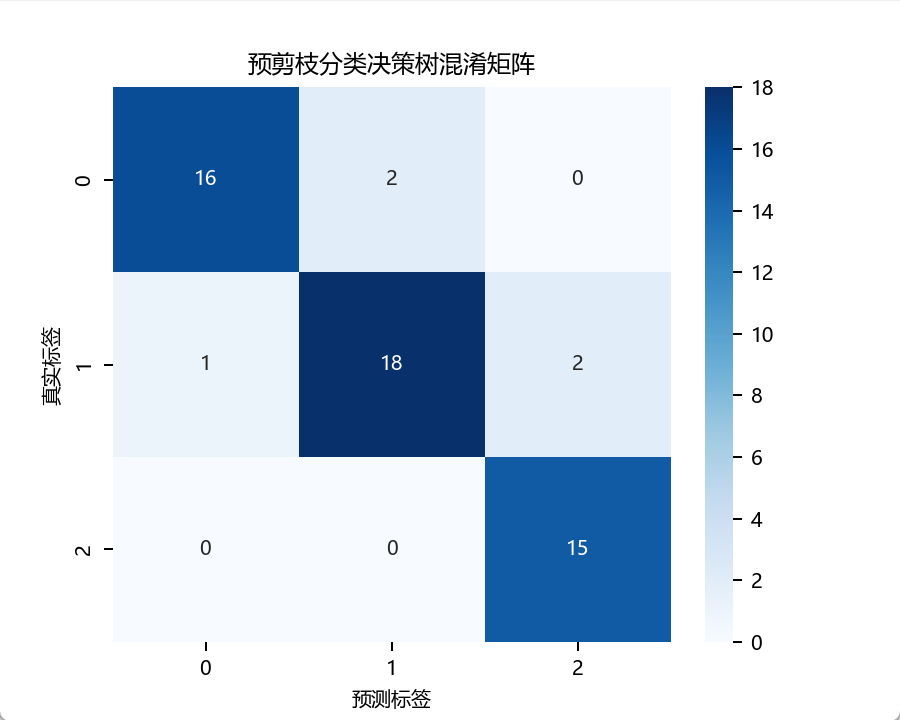
【人工智能】【Python】决策树实验
该实验利用决策树算法进行分类(葡萄酒数据集)与回归(加州房价数据集),对比预剪枝(控制最大深度等参数)和后剪枝(CCP算法)策略对模型性能的影响。通过网格搜索优化超参数,结合SMOTE处理...

【人工智能】作物叶片病害分类去背景方法&MaxViT混合玉米数据集&模型改进实验-2025年3月22日人工智能组会总结
本次组会汇报了两项研究进展:一、提出基于图像切割与标注的作物叶片病害分类去背景方法,采用小型Inception模型验证泛化性,探讨OpenCV预处理或语义分割去背景的可行性;二、融合多源玉米数据...

【人工智能】通过玉米叶片病害识别提高作物生产力与可持续性:利用大型数据集与先进视觉Transformer模型
本文提出一种轻量化改进的MaxViT模型,通过集成SE模块和GRN技术优化结构,并结合多源数据集(5234张图像)进行玉米叶片病害检测。实验表明,该模型在四分类任务中准确率达99.24%,推理速度达0.0...






