

本实验使用K近邻分类算法对sklearn葡萄酒数据集进行分类,采用标准化预处理、网格搜索优化超参数(k值、距离度量、权重方式)并结合5折交叉验证确保模型稳定性。最终,最佳模型在测试集上实现100%准确率,并通过PCA降维可视化数据分布,分析K值对模型性能的影响。
描述算法、数据集、及所设计的实验方案
描述算法: 实验采用K近邻分类算法,算法主要思路是基于特征空间中的距离度量实现分类决策。关键参数包含k值选取(我的实验将在1-15范围内测试)、权重计算方式(均匀权重与距离权重)、距离度量(曼哈顿距离与欧氏距离)。通过网格搜索实现参数空间遍历优化,并且配合5折交叉验证确保参数稳定性。
数据集特性: 使用sklearn自带的葡萄酒数据集,包含13个特征(酒精含量、苹果酸浓度等)与3个葡萄栽培变种分类标签。样本总量178条,特点是小样本但是维度大。前5个样本数据显示特征值的差距比较大,必须进行标准化预处理。
实验设计: 先加载葡萄酒数据集,然后打印数据集的基本参数和前五个样本数据。之后对数据进行标准化的预处理,分层拆分数据集。设置网格搜索的参数,创建knn对象,然后进行网格搜索,得到最优参数。接着使用最优参数进行预测,得到测试集准确率,输出分类报告(包含精确率,召回率,F1分数等评估指标)。最后进行数据的可视化,使用PCA降维,分析找到两个主成分,用来查看数据集的数据分布。然后绘制K值与准确率关系的曲线。
实验详细操作步骤或程序清单
# 机器学习第一次实验
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.decomposition import PCA
import pandas as pd
# 加载葡萄酒数据集
wine = datasets.load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
target_names = wine.target_names
# 数据集的描述
print("数据集的相关参数:")
print("特征数量:", X.shape[1])
print("样本数量:", X.shape[0])
print("特征名称:", feature_names)
print("类别名称:", target_names)
print("\n前5个样本数据预览:\n", pd.DataFrame(X[:5], columns=feature_names))
# 数据预处理:标准化
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 使用网格搜索进行参数调优
param_grid = {
'n_neighbors': list(range(1, 16)),
'weights': ['uniform', 'distance'],
'p': [1, 2] # p=1:曼哈顿距离,p=2:欧氏距离
}
knn = KNeighborsClassifier()
grid_search = GridSearchCV(knn, param_grid, cv=5, scoring='accuracy', n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
best_params = grid_search.best_params_
print("\n网格搜索得到的最佳参数:", best_params, "\n注:p=1是曼哈顿距离,p=2是欧氏距离")
# 使用最佳模型进行预测
best_knn = grid_search.best_estimator_
y_pred = best_knn.predict(X_test)
# 模型评估
print("\n测试集准确率:", best_knn.score(X_test, y_test)*100, "%")
print("\n分类报告:\n", classification_report(y_test, y_pred, target_names=target_names))
# 可视化部分
# 设置字体
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
plt.rcParams["figure.dpi"] = 160
plt.rcParams["font.size"] = 8
# 1. 数据分布可视化(使用PCA降维)
plt.figure(figsize=(12, 5))
# PCA降维到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_train)
plt.subplot(121)
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_train, cmap='viridis')
plt.xlabel('主成分1')
plt.ylabel('主成分2')
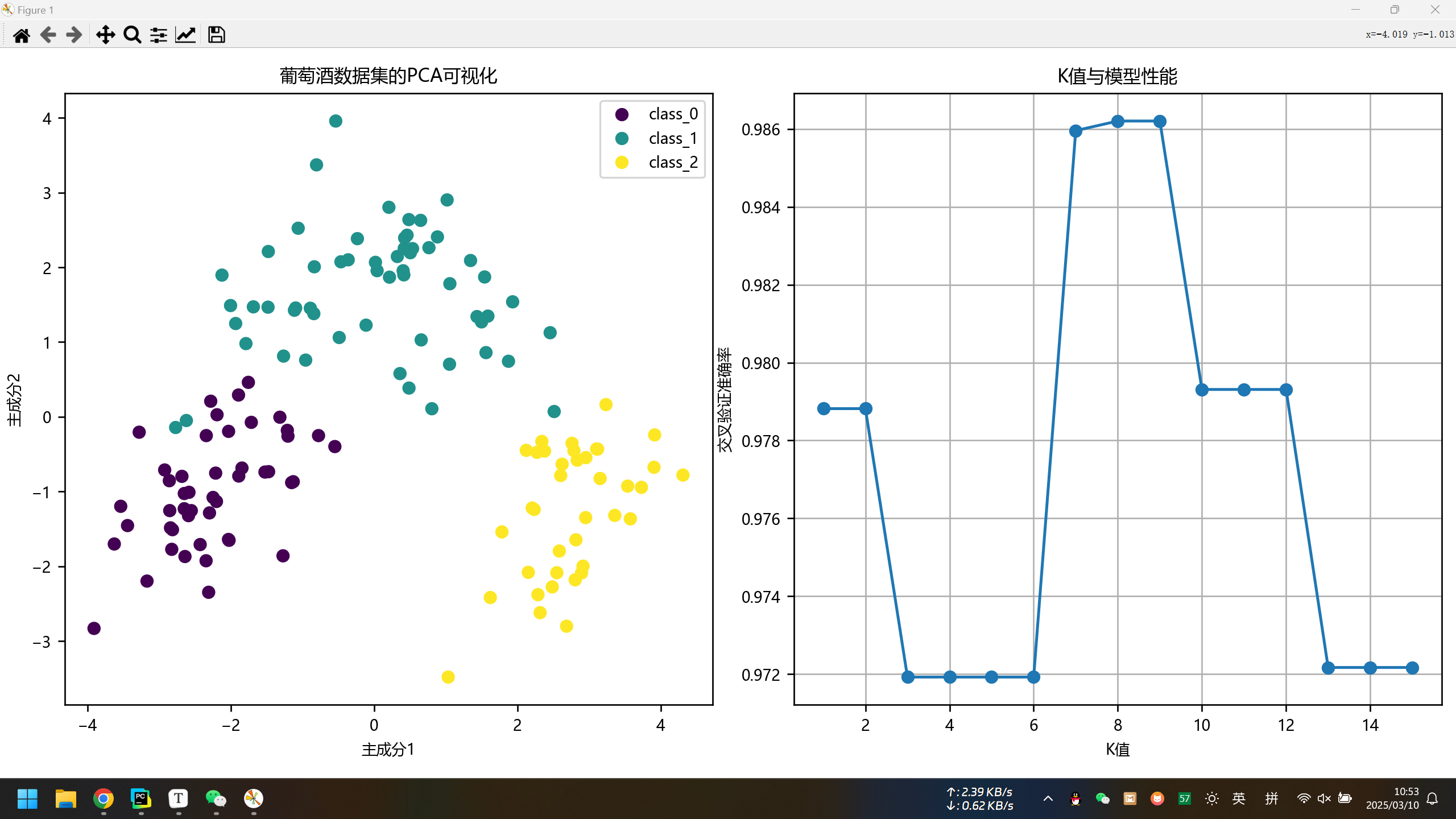
plt.title('葡萄酒数据集的PCA可视化')
plt.legend(handles=scatter.legend_elements()[0], labels=target_names.tolist())
# 2. K值与准确率关系曲线
results = grid_search.cv_results_
k_scores = []
for k in param_grid['n_neighbors']:
mask = [param['n_neighbors'] == k for param in results['params']]
k_scores.append(np.max(results['mean_test_score'][mask]))
plt.subplot(122)
plt.plot(param_grid['n_neighbors'], k_scores, marker='o')
plt.xlabel('K值')
plt.ylabel('交叉验证准确率')
plt.title('K值与模型性能')
plt.grid(True)
plt.tight_layout()
plt.show()
实验结果(上传实验结果截图或者简单文字描述)
控制台输出:
D:\AnacondaEnvs\PyTorch\python.exe D:\桌面\编程相关\04_IDE练习项目\sklearn\scikit-learn\Lab\lab01.py
数据集的相关参数:
特征数量: 13
样本数量: 178
特征名称: ['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
类别名称: ['class_0' 'class_1' 'class_2']
前5个样本数据预览:
alcohol malic_acid ash ... hue od280/od315_of_diluted_wines proline
0 14.23 1.71 2.43 ... 1.04 3.92 1065.0
1 13.20 1.78 2.14 ... 1.05 3.40 1050.0
2 13.16 2.36 2.67 ... 1.03 3.17 1185.0
3 14.37 1.95 2.50 ... 0.86 3.45 1480.0
4 13.24 2.59 2.87 ... 1.04 2.93 735.0
[5 rows x 13 columns]
网格搜索得到的最佳参数: {'n_neighbors': 8, 'p': 1, 'weights': 'uniform'}
注:p=1是曼哈顿距离,p=2是欧氏距离
测试集准确率: 100.0 %
分类报告:
precision recall f1-score support
class_0 1.00 1.00 1.00 12
class_1 1.00 1.00 1.00 14
class_2 1.00 1.00 1.00 10
accuracy 1.00 36
macro avg 1.00 1.00 1.00 36
weighted avg 1.00 1.00 1.00 36
进程已结束,退出代码为 0
绘制的Matplotlib图像:
疑难小结(总结个人在实验中遇到的问题或者心得体会)
这次实验踩了两个新坑:数据降维可视化(PCA)与自动化调参。这也是我第一次用PCA,我去CSDN查了一下,最头疼的是理解那两个主成分的实际意义。葡萄酒数据集输入了13个化学指标的参数,输出却变成两个抽象维度,是一种信息压缩的感觉。
网格搜索虽然自动遍历了195种参数组合(15个k值×2种权重×2种距离×5折验证),如果要是扩展到更多超参数,和更大的数据集,时间成本肯定会指数级上升。
从实验结果上看,这次实验使用网格搜索得到的参数(k=8,使用哈曼顿距离,使用均匀权重)进行测试集的测试,得到的准确率达到了100%,其他参数(精确率,召回率, F1分数)也都是100%。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
























暂无评论内容