


关于新人与PPT
PPT要求:页码清晰,首页写清汇报日期,班级,姓名。各种专有名词该大写的要大写,例如PyTorch。如果自己不清楚的话,模型全称要写好,汇报模型性能或者参数对比时尽量使用表格,文本不要过于密集,放出原论文的图片或者表格要进行较为细致的讲解,PPT最后写下周的任务规划。
入门先把最基本的模型:LeNet,GoogLeNet,ResNet,VGG等基础模型跑通,回避绝大多数理论知识,快速入门PyTorch,打好Python基础(学完类就差不多了),学会Debug,分析超参数对Val Acc,Train Acc的影响,把不懂的专业术语尽快查清,学会使用tensorboard或者matplotlib绘制训练过程。
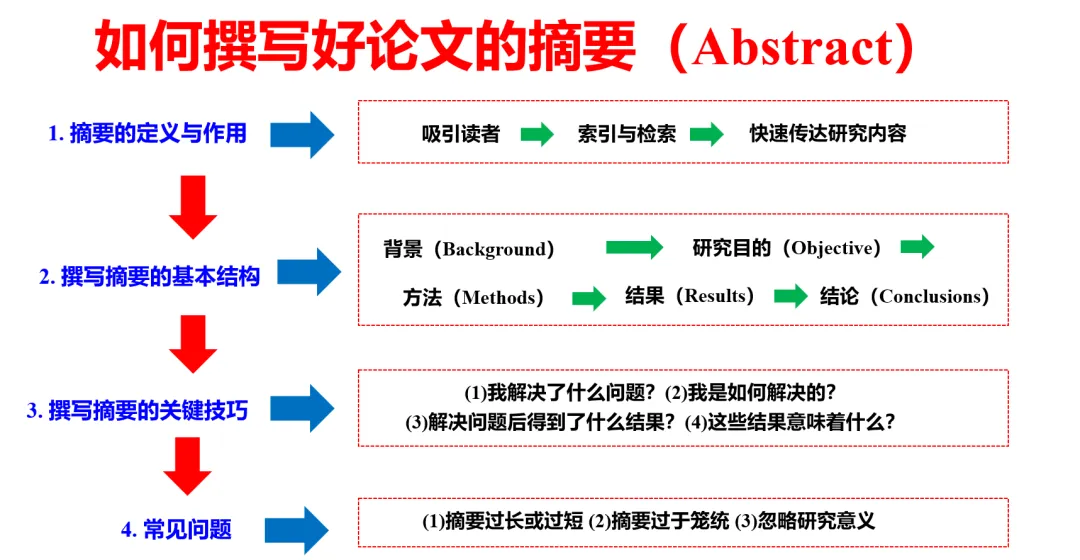
怎么看论文
选定一个领域后,先阅读对应领域的综述(Review、Survey),尽量找新的看。综述里一般会提到常用的模型方法,数据集,评价指标等关键信息。这也是踏入对应领域的“敲门砖”。
尽量选有源代码的论文,链接一般都在Abstract最后。学会自己跟着Readme搭建模型并运行,复现论文中的实验结果,这样原论文才有可靠性。注意!一定要多跑模型,积累经验十分重要。
论文阅读时应该找高水平论文(顶会、顶刊、中文四大学报),汇报时要列出论文等级(引用量,发布于哪里)、作者团队介绍、论文的动机、核心方法、实验结果、对比算法、数据集、有没有继续改进的空间、论文读后感想等内容。
论文阅读建议保留痕迹,可以打印出来,在纸上标注,或者电子版中进行标注。
带着批判的态度读论文,其他领域的方法在自己领域模型上改进时如果效果不好要自己独立思考,分析数据集和哪个分类不好,尽早找到自己的基础模型。
及时记录学习过程中的踩坑、技术难题的解决等,发表博客,组会时可以简单展示。
只盲目的读论文,永远发不出论文。
关于数据集
数据集如果文件太少,可以尝试数据增强来扩充数据集。一般的方式有:旋转、翻转、缩放、裁剪、平移、改变亮度、改变对比度、添加噪声、颜色抖动、仿射变换、透视变换、镜像、模糊、光照变化、随机遮挡、透视扭曲、灰度化、色调调整、过采样、欠采样。
关于图像预处理:灰度化、归一化、标准化、直方图均衡化、去噪、图像平滑(如高斯模糊、中值滤波)、锐化、边缘检测、图像旋转、裁剪、缩放、翻转、数据增强(如翻转、旋转、裁剪、缩放等)、色彩空间转换(如RGB到HSV)、图像亮度调整、对比度调整、数据扩充(如随机裁剪、加噪声等)。
不要随便找数据集,一定是在领域内比较有说服力的数据集才可以。有能力也可以自制数据集,可作为创新点。
关于做实验(跑模型)
模型同一个参数最少跑3次,取平均和最高,一般跑5次就够了。源代码的运行骨架最好学习一下,分析模型的构造函数,forward函数等较为重要的内容,这样对比结构图来看会豁然开朗。
关于改进模型
改进不能直接用别人的(即插即用)模块,要加自己的创新(简单的替换不算是创新),注意输入输出的特征图维度。
选定基础模型尽量选近一年的,性能接近最高水平的。如果选的是有一系列的模型,例如YoLo,则尽量选新的。
创新点怎么找?找顶会文章,其他小领域的方法。有想法——>在基础模型上做出小改动——>实验
如果有创新点,一定要给这个创新点找一个动机(一般看数据集的分类结果找,多分析数据集中图片的特征)。
关于写项目书(部分适用于写论文)
多结合最新政策。一些细节问题不要犯,例如Figure1.这种对图像的解释,格式统一。题目最好不要用模型名字,除非模型非常出名,一般就写“基于xxx的改进”。
段落间不要有空格,1.5倍行间距,表的标题在表上,图的标题在图下。
关于写论文
已经提升了1.5%左右的精度,较大的创新点有2个,模型有一定的优点和创新性。
大致的流程:先整理实验部分——>评价指标——>方法论——>相关工作——>介绍——>摘要——>总结。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。






















暂无评论内容