

![图片[1] - AI科研 编程 读书笔记 - 【人工智能】无归一化的Transformer - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/04/01/67eb7cad20872.png)
GitHub:https://github.com/jiachenzhu/DyT
作者及所属机构
- Jiachen Zhu(朱佳晨):来自纽约大学(New York University)和Meta的人工智能研究实验室(FAIR,Facebook AI Research)。
- Xinlei Chen(陈鑫磊):来自Meta的人工智能研究实验室(FAIR)。
- Kaiming He(何恺明):来自麻省理工学院(MIT)。
- Yann LeCun:来自纽约大学(New York University)和Meta的人工智能研究实验室(FAIR)。
- Zhuang Liu(刘壮):来自普林斯顿大学(Princeton University),并且是该项目的负责人。
团队特点
- 跨机构合作:团队成员来自不同的顶尖学术机构和工业界研究实验室,这种跨机构的合作有助于整合各方资源和优势,推动研究的深入开展。
- 领域多样性:团队成员在深度学习、计算机视觉、自然语言处理等多个领域具有丰富的研究经验,能够从不同角度对问题进行分析和解决。
- 学术与工业结合:团队中既有来自学术界的学者,也有来自工业界的研究人员,这种结合有助于将理论研究与实际应用相结合,提高研究成果的实用性和影响力。
- 知名学者参与:团队中包括像何恺明和Yann LeCun这样的知名学者,他们在深度学习领域具有重要的影响力,他们的参与为研究提供了强大的支持和指导。
这个作者团队具有强大的研究实力和丰富的经验,他们的合作为这篇论文的研究成果提供了有力的保障。
动机(Motivation)
- 传统观点:归一化层(如Layer Norm, LN)被视为现代神经网络(尤其是Transformer)的必需组件,用于加速收敛和稳定训练。
- 核心观察:作者发现LN的输出输入映射呈现类似tanh的S型曲线,其主要作用是通过非线性压缩极端值,而非传统的线性标准化。
- 挑战假设:提出是否可以通过更简单的非线性操作(如动态调整的tanh)替代归一化层,同时保持或提升模型性能。
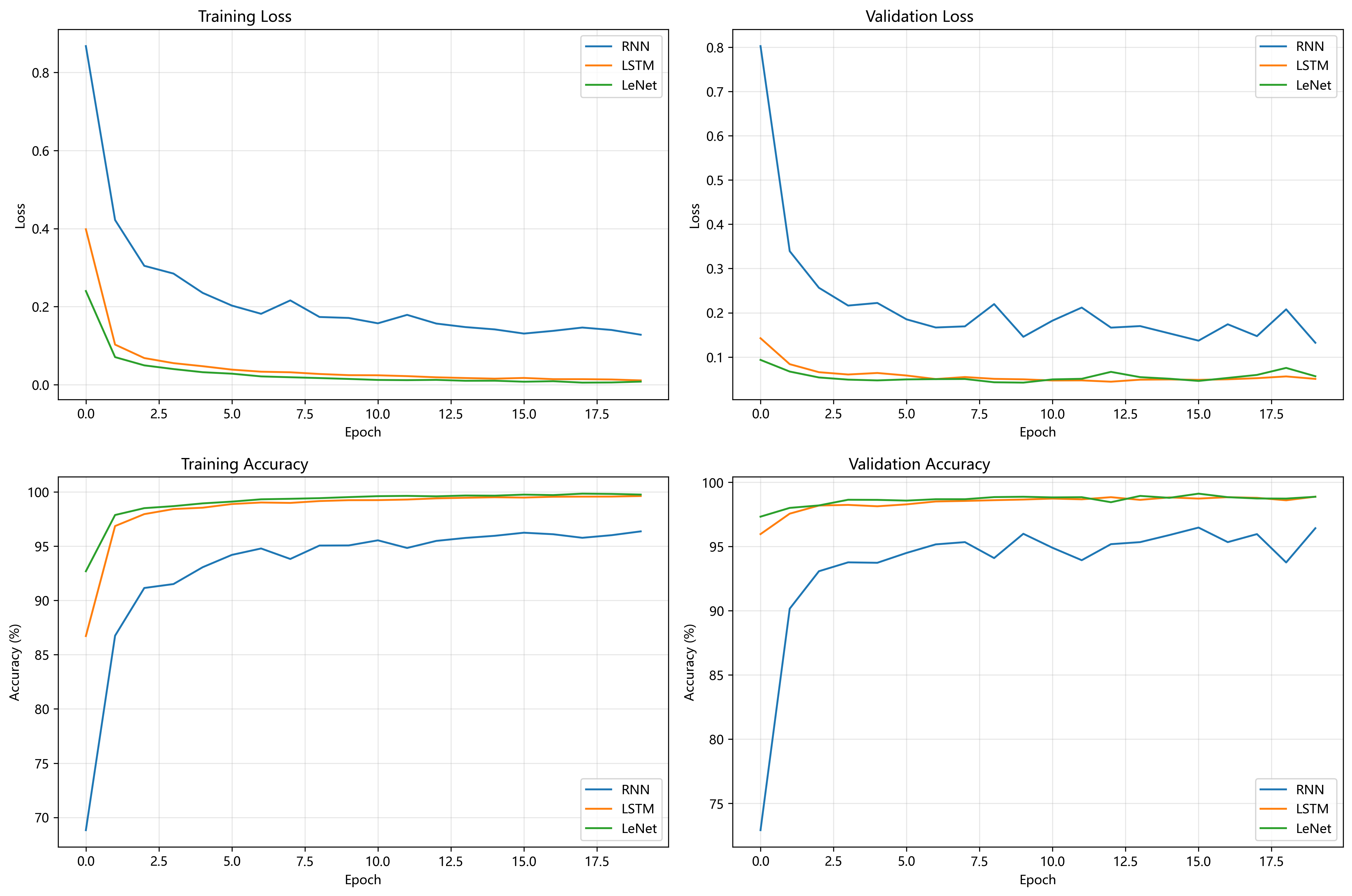
核心方法(Core Method)
Dynamic Tanh (DyT):
- 定义:DyT(x) = γ * tanh(αx) + β,其中α为可学习标量参数,γ和β为通道级仿射参数。
- 设计灵感:通过tanh的S型曲线模仿LN的非线性压缩效应,α动态调整输入范围以适配不同层和任务。
- 实现方式:直接替换Transformer中的LN或RMSNorm层,无需修改其他结构或超参数。
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】无归一化的Transformer - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/04/01/67eb7dedc3a41.png)
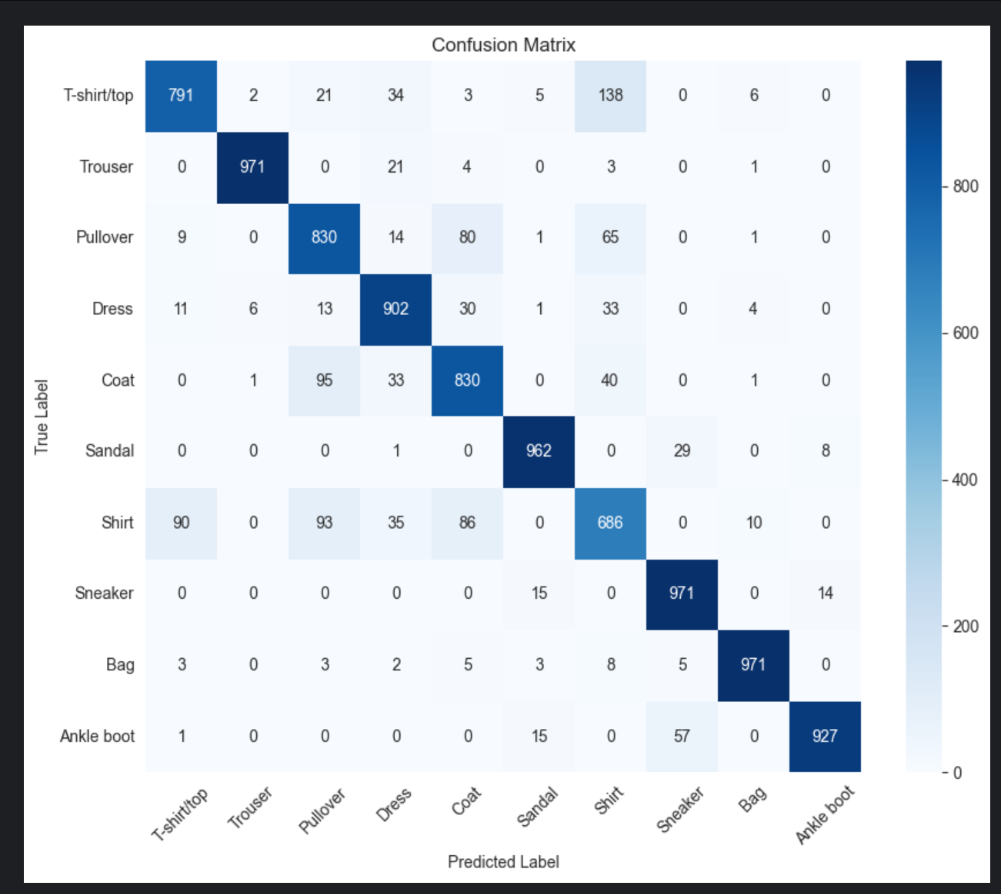
实验结果(Experimental Results)
- 任务覆盖:
- 监督学习(ImageNet分类):ViT和ConvNeXt模型使用DyT性能持平或优于LN(ViT-L提升0.5%)。
- 自监督学习(MAE、DINO):DyT与LN性能相当,部分任务(DINO ViT-B)提升0.4%。
- 扩散模型(DiT):DyT在FID指标上表现接近或更优(DiT-B降低1.0)。
- 大语言模型(LLaMA 7B-70B):DyT与RMSNorm在训练损失和zero-shot任务上表现一致。
- 语音与DNA建模(wav2vec 2.0、HyenaDNA):性能与LN相当。
- 效率优势:DyT在LLaMA 7B上减少52.4%的归一化层计算时间,整体推理速度提升7.8%。
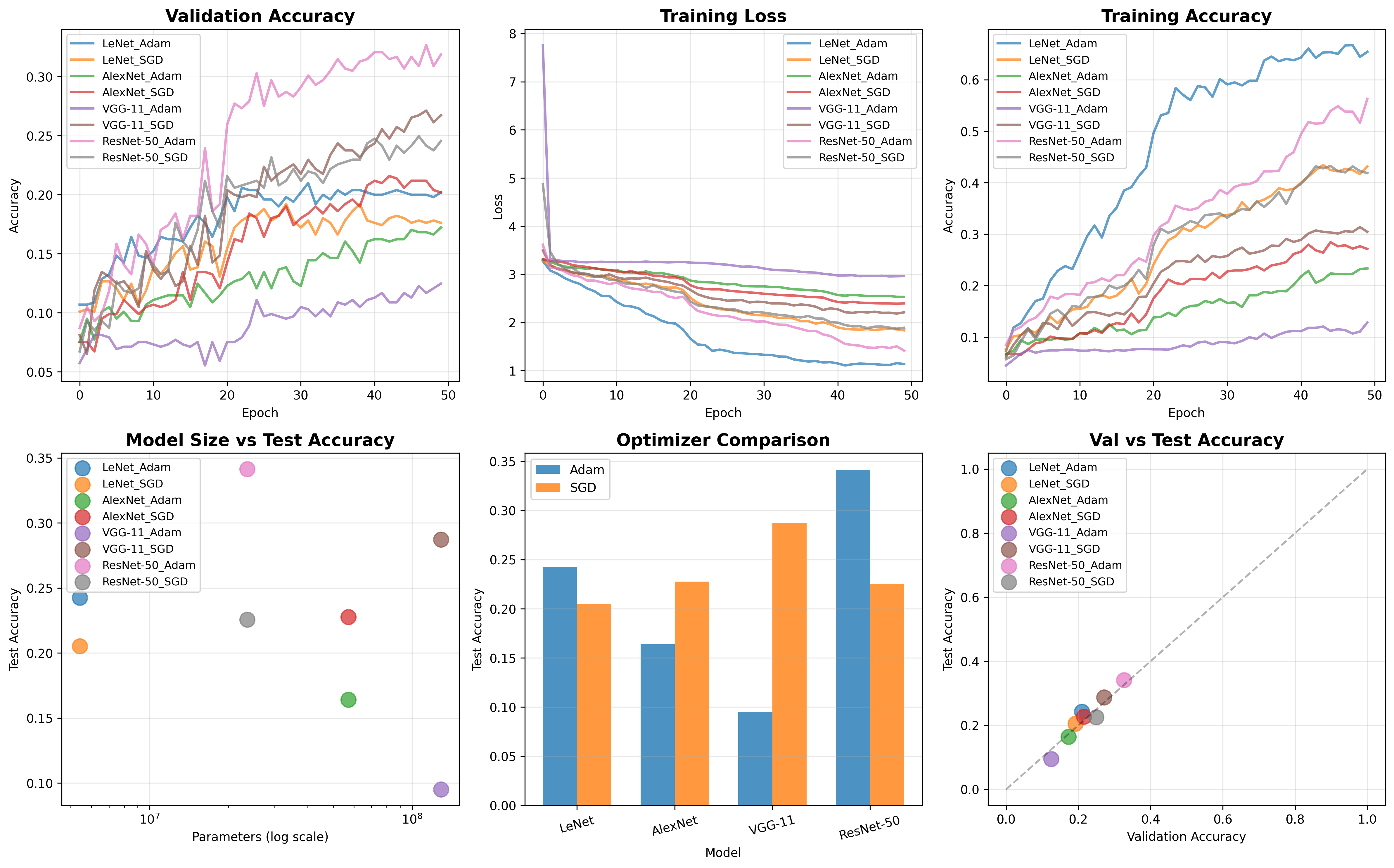
对比算法(Comparisons)
- 替代方法:与Fixup、SkipInit(初始化优化)和σReparam(权重归一化)相比,DyT在ViT和MAE任务中显著更优(ViT-B准确率82.8% vs. Fixup 77.2%)。
- 消融实验:移除tanh或α导致性能下降(ViT-B从82.5%降至81.1%),证明两者缺一不可。
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】无归一化的Transformer - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/04/01/67eb7e31b5660.png)
数据集(Datasets)
- 图像:ImageNet-1K、扩散模型参考批次。
- 语言:The Pile(200B tokens)、OpenLLaMA评估任务。
- 语音:LibriSpeech。
- DNA:GenomicBenchmarks(人类参考基因组GRCh38)。
改进空间(Limitations & Future Work)
- 局限性:
- DyT在经典卷积网络(如ResNet、VGG)中替换BatchNorm效果不佳(ResNet-50准确率下降7.3%)。
- 大语言模型需针对注意力块和其他模块调整α初始化,增加调参复杂性。
- 未来方向:
- 探索DyT在非Transformer架构(如RNN、GNN)中的适用性。
- 研究如何自动适配不同归一化层类型(如GroupNorm)。
- 优化LLM中α的初始化策略以减少人工干预。
总结
DyT通过简单的动态tanh操作挑战了归一化层的必要性,在多种任务中验证了其有效性,并为理解归一化机制提供了新视角。其高效性和易用性使其成为轻量级模型设计的潜在选择,但在非Transformer架构中的泛化能力仍需进一步探索。
代码示例
import torch
import torch.nn as nn
from timm.layers import LayerNorm2d
class DynamicTanh(nn.Module):
def __init__(self, normalized_shape, channels_last, alpha_init_value=0.5):
super().__init__()
self.normalized_shape = normalized_shape
self.alpha_init_value = alpha_init_value
self.channels_last = channels_last
self.alpha = nn.Parameter(torch.ones(1) * alpha_init_value)
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
def forward(self, x):
x = torch.tanh(self.alpha * x)
if self.channels_last:
x = x * self.weight + self.bias
else:
x = x * self.weight[:, None, None] + self.bias[:, None, None]
return x
def extra_repr(self):
return f"normalized_shape={self.normalized_shape}, alpha_init_value={self.alpha_init_value}, channels_last={self.channels_last}"
def convert_ln_to_dyt(module):
module_output = module
if isinstance(module, nn.LayerNorm):
module_output = DynamicTanh(module.normalized_shape, not isinstance(module, LayerNorm2d))
for name, child in module.named_children():
module_output.add_module(name, convert_ln_to_dyt(child))
del module
return module_output
© 版权声明
1. 除特殊说明外,本网站所有原创文章的版权归作者所有,未经授权,禁止以任何形式(包括但不限于转载、摘编、复制、镜像等)发布至任何平台。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
THE END
























暂无评论内容