

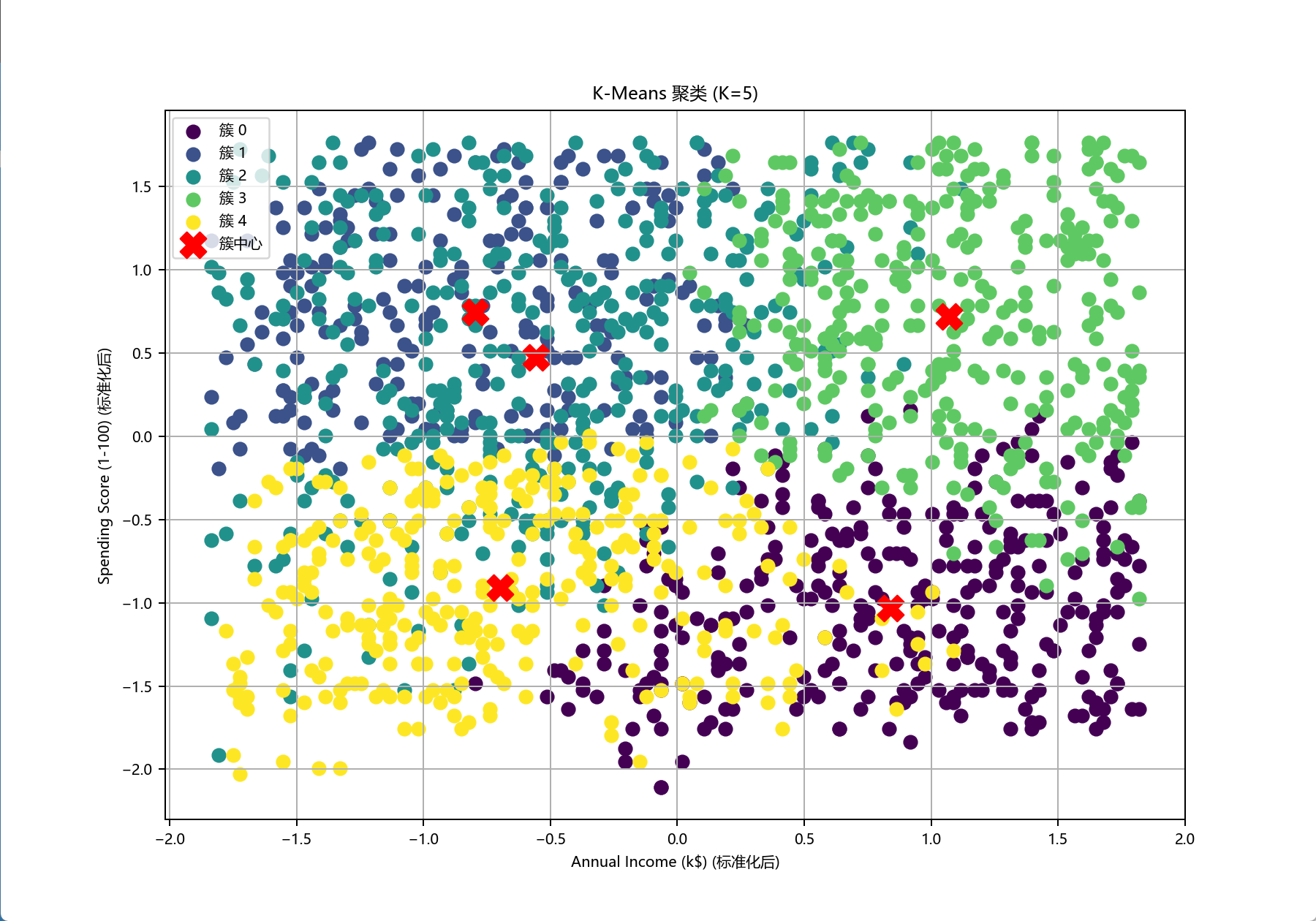
本次我记录一下CV分类任务的数据集分割代码。这次的分割以Plant Village数据集为例。这个数据集是用于农作物病虫害叶片分类领域的。首先我们拿到的原始数据集一般是一个大文件夹内有多个以分类名称命名的子文件夹。这是我们需要准备的原始数据集。如下图所示:
![图片[1] - AI科研 编程 读书笔记 - 【人工智能】计算机视觉分类任务的数据集分割暨Train+Val数据集处理代码 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/02/13/67addb7a448c5.png)
我们将要生成三个文件:class_indices.json、train_list.txt 和 val_list.txt。以下是这些文件的示例:
# class_indices.json
{
"Bacterial_spot": 0,
"Early_blight": 1,
"Late_blight": 2,
"Leaf_Mold": 3,
"Septoria_leaf_spot": 4,
"Spider_mites Two-spotted_spider_mite": 5,
"Target_Spot": 6,
"Tomato_Yellow_Leaf_Curl_Virus": 7,
"Tomato_mosaic_virus": 8,
"healthy": 9
}
# train_list.txt
./train/Bacterial_spot/image (1).jpg 0
./train/Bacterial_spot/image (2).jpg 0
./train/Bacterial_spot/image (3).jpg 0
./train/Bacterial_spot/image (4).jpg 0
./train/Bacterial_spot/image (5).jpg 0
./train/Bacterial_spot/image (6).jpg 0
./train/Bacterial_spot/image (7).jpg 0
./train/Bacterial_spot/image (8).jpg 0
./train/Bacterial_spot/image (9).jpg 0
# 更多省略
# val_list.txt
./val/Bacterial_spot/image (1915).jpg 0
./val/Bacterial_spot/image (1916).jpg 0
./val/Bacterial_spot/image (1917).jpg 0
./val/Bacterial_spot/image (1918).jpg 0
./val/Bacterial_spot/image (1919).jpg 0
./val/Bacterial_spot/image (1920).jpg 0
./val/Bacterial_spot/image (1921).jpg 0
./val/Bacterial_spot/image (1922).jpg 0
./val/Bacterial_spot/image (1923).jpg 0
# 更多省略
下面是用于分割数据集的代码:
import os
import json
import shutil
from sklearn.model_selection import train_test_split
import re
# 配置原始数据集文件夹路径
original_dataset_dir = 'Tomato_orgin' # 请替换为原始数据集的文件夹路径
target_dataset_dir = "Tomato"
train_dir = os.path.join(target_dataset_dir, 'train') # 目标训练集的文件夹路径
val_dir = os.path.join(target_dataset_dir, 'val') # 目标验证集的文件夹路径
# 创建目标文件夹
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
# 初始化
class_indices = {}
train_list = []
val_list = []
# 获取原始数据集中的所有子文件夹(每个子文件夹是一个类别)
categories = os.listdir(original_dataset_dir)
categories.sort() # 保证按照文件名顺序
# 用于提取文件名中的数字部分进行排序
def sort_key(image_name):
# 提取文件名中的所有数字部分,并将其按整数顺序排序
numbers = re.findall(r'\d+', image_name)
return [int(num) for num in numbers]
# 生成class_indices.json
for idx, category in enumerate(categories):
class_indices[category] = idx
category_train_dir = os.path.join(train_dir, category)
category_val_dir = os.path.join(val_dir, category)
os.makedirs(category_train_dir, exist_ok=True)
os.makedirs(category_val_dir, exist_ok=True)
# 获取当前类别的所有图片文件(只考虑jpg文件)
category_path = os.path.join(original_dataset_dir, category)
images = [f for f in os.listdir(category_path) if f.endswith('.jpg')]
# 按照文件名中的数字部分进行排序
images.sort(key=sort_key)
# 切分数据集,9:1的比例
train_images, val_images = train_test_split(images, test_size=0.1, shuffle=False)
# 将图片复制到训练集和验证集文件夹
for image in train_images:
shutil.copy(os.path.join(category_path, image), os.path.join(category_train_dir, image))
# 在路径前加上 ./ 相对路径,并添加类别编号
train_list.append(f"./train/{category}/{image} {class_indices[category]}")
for image in val_images:
shutil.copy(os.path.join(category_path, image), os.path.join(category_val_dir, image))
# 在路径前加上 ./ 相对路径,并添加类别编号
val_list.append(f"./val/{category}/{image} {class_indices[category]}")
# 保存class_indices.json
with open(os.path.join(target_dataset_dir, 'class_indices.json'), 'w') as f:
json.dump(class_indices, f, indent=4)
# 保存train_list.txt
with open(os.path.join(target_dataset_dir, 'train_list.txt'), 'w') as f:
f.write("\n".join(train_list))
# 保存val_list.txt
with open(os.path.join(target_dataset_dir, 'val_list.txt'), 'w') as f:
f.write("\n".join(val_list))
print("数据集处理完成,文件已保存:class_indices.json, train_list.txt, val_list.txt")
注意如果没有对应的模块请自行安装。需要编辑original_dataset_dir和target_dataset_dir两个文件夹参数。文件夹内图片只读取.jpg后缀(区分大小写),如果您的图片是其他格式可以在源代码中修改读取的文件后缀。
© 版权声明
1. 除特殊说明外,本网站所有原创文章的版权归作者所有,未经授权,禁止以任何形式(包括但不限于转载、摘编、复制、镜像等)发布至任何平台。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
THE END
























暂无评论内容