

![图片[1] - AI科研 编程 读书笔记 - 【人工智能】DCGAN文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/19/6944a213c8e11.png)
参考文献:https://arxiv.org/abs/1511.06434
动机
在计算机视觉领域,使用CNN进行监督学习(如分类任务)已经非常成功,但在无监督学习方面关注较少。当时的GAN(Generative Adversarial Networks)虽然概念新颖,但训练非常不稳定,经常生成毫无意义的噪声输出,且很难理解网络内部到底学到了什么。作者的动机主要有两点:
①希望填补CNN在监督学习的成功与无监督学习之间的鸿沟。
②提出一种架构约束,使CNN与GAN的结合(即DCGAN)能够稳定训练,并证明其学到了有意义的层级特征表示,可用于下游任务。
创新点
为了让GAN在卷积架构下稳定训练,作者经过大量试错,总结了一套核心的架构设计原则(这也是DCGAN最核心的贡献):
①取消池化层:在判别器(Discriminator)中用步长卷积(Strided Convolution)代替池化,让网络自己学习下采样;在生成器(Generator)中用分数步长卷积(Fractional-strided Convolution,常被称为转置卷积)代替上采样。
②取消全连接层:去掉了传统CNN末端的全连接层,直接将最高层卷积特征连接到输出,改用全局平均池化(Global Average Pooling)虽然增加稳定性但降低了收敛速度,最终选择了直接连接。
③使用Batch Normalization(BN):在生成器和判别器中广泛使用BN层,能防止生成器坍缩到单一模式(Mode Collapse),并解决初始化差的问题。注意:生成器的输出层和判别器的输入层不加BN。
④激活函数选择:生成器内部层全部使用ReLU,输出层使用Tanh(将像素值映射到[-1, 1]);判别器内部层全部使用LeakyReLU(slope=0.2),防止梯度稀疏。
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】DCGAN文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/19/6944a531ec11d.png)
实验结果和对比算法
这篇论文主要在无监督特征学习的背景下进行了对比:
①数据集:LSUN Bedroom(超300万张)、Imagenet-1k、SVHN(街景门牌号)、CIFAR-10以及自建的人脸数据集。
②对比算法(作为特征提取器):作者将训练好的判别器作为特征提取器,在CIFAR-10和SVHN上训练简单的线性分类器(SVM),对比了K-means、Auto-encoders、Exemplar CNN等传统无监督方法。
③性能表现:在CIFAR-10上,DCGAN提取的特征达到了82.8%的准确率,优于当时所有基于K-means的方法;在SVHN上,仅用1000个标签样本就达到了22.48%的错误率,刷新了当时的小样本学习SOTA。
作者在LSUN(卧室场景)、Imagenet-1k和自建的人脸数据集上进行了训练,结果非常有说服力:
①图像生成质量:生成的卧室和人脸图片非常逼真,远超当时的其他非参数化方法。即使训练一轮后(Epoch 1),模型也没有简单记忆训练集,而是开始生成似是而非的结构。
②隐空间漫游(Latent Space Walk):在潜在空间Z中进行插值(Walking),生成的图像变化是平滑的(例如从没有窗户的房间慢慢渐变出窗户),证明模型没有过拟合,而是学到了数据的流形分布。
③向量算术特性:这是最让人惊艳的发现。类似于NLP中的“King – Man + Woman = Queen”,DCGAN在图像向量上也展现了算术特性。例如:[戴眼镜男人的向量] – [不戴眼镜男人的向量] + [不戴眼镜女人的向量] = [戴眼镜女人的向量]。此外,还能通过向量运算改变人脸的朝向。
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】DCGAN文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/19/6944a5ebdb330.png)
虽然DCGAN极大地提升了稳定性,但作者也诚实地指出了局限性:
①训练依然有不稳定性:当训练时间过长时,模型有时仍会发生滤波器坍缩,导致输出出现振荡。
②扩展领域:作者建议未来将此框架扩展到视频(帧预测)和音频(语音合成)领域。
③隐空间探索:建议深入研究潜在空间的属性,这在后来的StyleGAN等工作中得到了极大的发展。
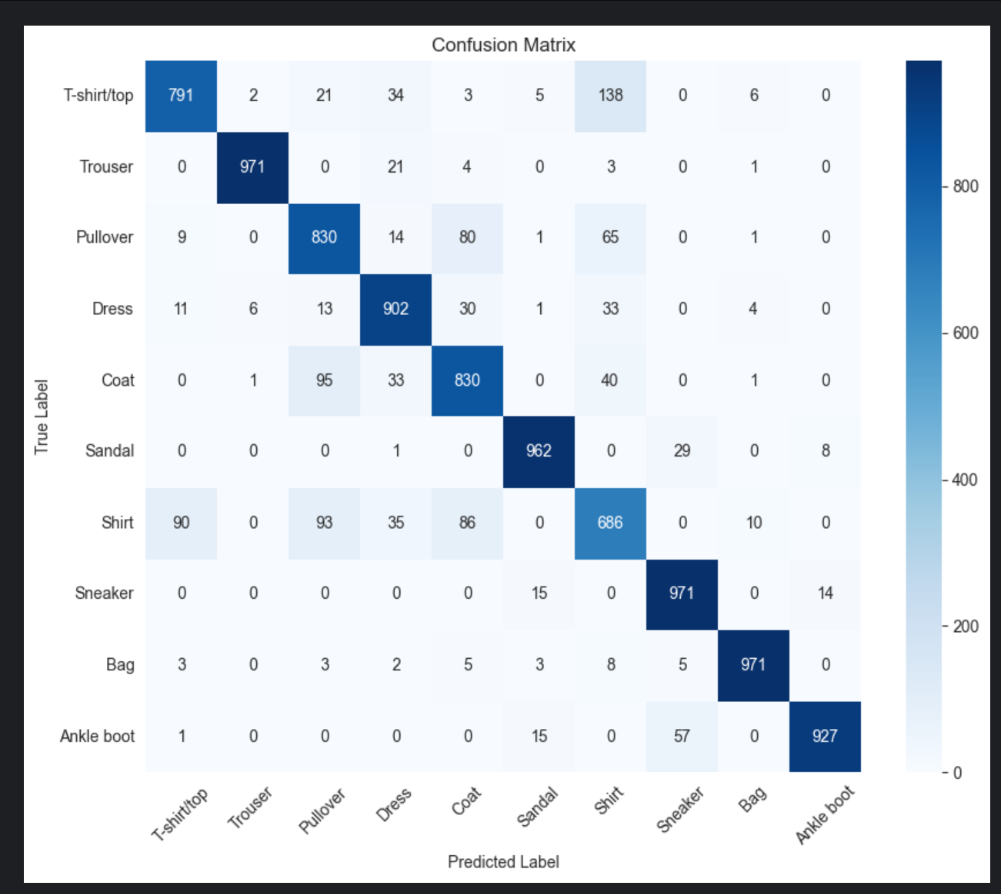
模型复现和分析
![图片[4] - AI科研 编程 读书笔记 - 【人工智能】DCGAN文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/19/6944a694e1b2e.png)
![图片[5] - AI科研 编程 读书笔记 - 【人工智能】DCGAN文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/19/6944a6a337758.png)
![图片[6] - AI科研 编程 读书笔记 - 【人工智能】DCGAN文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/19/6944a6b7b10bc.png)
![图片[7] - AI科研 编程 读书笔记 - 【人工智能】DCGAN文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/19/6944a6c8b4603.png)
与其他模型的对比
在Introduction和Related Work部分,作者主要对比了当时的生成模型现状:
①与传统GAN(Goodfellow et al., 2014)对比:传统GAN由全连接层构成,处理复杂图像能力弱,且极不稳定。DCGAN引入卷积结构后解决了生成自然图像的问题。
②与Auto-Encoders(VAE等)对比:当时的变分自编码器生成的图像往往模糊不清,而DCGAN生成的图像清晰锐利。
③与LAPGAN对比:LAPGAN虽然提升了分辨率,但需要多级金字塔训练,且引入了噪声导致图像看起来“抖动”。DCGAN是端到端的单一模型,生成更连贯。
与其他模型的对比表
| 模型名称 | 模型架构类型 | 核心生成 / 学习机制 | 图像生成质量 | 特征提取表现(CIFAR-10 Accuracy) | 主要痛点 / 局限 |
|---|---|---|---|---|---|
| DCGAN(本文) | 深层卷积神经网络(CNN) | 对抗生成(Adversarial) | 清晰、连贯 | 82.8% | 首次成功将 CNN 与 GAN 结合,去除了全连接层与池化层; 训练过程相对稳定,隐空间具备向量算术等良好性质。 |
| Original GAN(2014) | 全连接网络(Fully Connected) | 对抗生成(Adversarial) | 噪点多、语义不可理解 | 未报告 | 训练极不稳定,容易产生无意义噪声, 难以扩展到高分辨率图像生成。 |
| VAE(变分自编码器) | 概率图模型 + 神经网络 | 变分推断(Variational) | 结构完整但偏模糊 | 通常低于 GAN | 生成样本倾向于平滑, 缺乏高频细节,视觉效果类似模糊滤镜。 |
| LAPGAN(拉普拉斯金字塔 GAN) | 多级金字塔 CNN | 逐级迭代生成 | 质量尚可,但存在物体抖动 | 未主要用于分类 | 架构复杂,非端到端生成; 生成图像中常伴随明显噪声纹理。 |
| K-means(Baseline) | 聚类算法(非深度学习) | 聚类中心学习 | 无生成能力 |
80.6%(1 层) 82.0%(3 层) | 传统强基线方法, DCGAN 在特征提取能力上明显优于该方法。 |
| Exemplar CNN | 判别式 CNN | 代理任务(Surrogate Task) | 无生成能力 | 84.3% | 当时无监督分类的 SOTA 方法, 但无法生成图像,功能较为单一。 |
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
























暂无评论内容