

![图片[1] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693baa63584d3.png)
发表在《Advances In Neural Information Processing Systems》期刊,EI检索。
链接:https://proceedings.neurips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
动机
利用新出现的大规模数据集(ImageNet)和强大的计算资源(GPU),来训练一个足够深、足够大的卷积神经网络,以解决以往方法难以处理的大规模视觉识别问题,并验证深度模型在这一任务上的巨大潜力。
创新点
ReLU 非线性激活函数:使用ReLU的深度CNN比使用tanh的同等网络训练速度快数倍。这是能够成功训练如此大型模型的关键因素之一。
多GPU并行训练:作者将网络分布在两个GPU上。一半神经元在一个GPU上,另一半在另一个GPU上。
局部响应归一化:模仿了生物神经元中的“侧抑制”现象,对同一空间位置上、邻近的多个特征图(kernel maps)的ReLU激活值进行归一化,使得响应较大的神经元变得更突出,同时抑制周围的神经元。
重叠池化:传统的池化操作中,池化窗口的步长s等于窗口大小z,窗口之间不重叠。作者使用了重叠池化,即步长小于窗口大小。
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693baaa788974.png)
Conv1: 96个 11x11x3 的卷积核,步长为4。
Conv2: 256个 5x5x48 的卷积核。
Conv3: 384个 3x3x256 的卷积核。
Conv4: 384个 3x3x192 的卷积核。
Conv5: 256个 3x3x192 的卷积核。
FC6, FC7: 各有4096个神经元。
FC8 (Output): 1000个神经元(对应1000个类别)。
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693baac5d0692.png)
![图片[4] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693baacfa8372.png)
第一层卷积:
卷积核的大小为11×11 步长为 4
总的输出数量为96,分成两组,每组为48
根据卷积计算公式得:(227-11)/4+1=55
则得到特成图大小为96×55×55
每组为48×55×55
再经过ReLU激活函数,生成激活像素层,尺寸大小不变
最后通过池化处理:(55-3) / 2+1=27
得到两组27×27×48池化层数据
其余卷积操作同理。
![图片[5] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693bab0d081df.png)
![图片[6] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693bab2426d70.png)
全连接层中的Dropout:在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作(失活)
Dropout可以有效的减少过拟合现象。
数据集
ILSVRC-2010、ILSVRC-2012
改进空间
无监督预训练 (Unsupervised Pre-training):作者说尽管他们的实验没有使用任何无监督预训练,但他们希望这种方法会有所帮助。后续可以考虑这一方面。
网络规模和深度:作者明确指出,他们的结果随着网络变大和训练时间变长而改善。他们认为,当前模型的规模主要受限于GPU显存和可容忍的训练时间。未来的研究方向是构建更大、更深的网络,以逼近人类视觉系统的复杂性。
应用于视频数据:作者的最终目标之一是将非常大且深的卷积网络应用于视频序列。他们认为视频中的时序结构提供了静态图像所缺失的宝贵信息。
模型复现和分析
水果数据集:train1178张图片,val128张图片
![图片[7] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693bab682766a.png)
增加训练轮数可以提高测试准确率,特别是在Test Accuracy尚未收敛时。训练轮数过多可能导致过拟合,反而降低测试的准确率。
![图片[8] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693bab763427d.png)
在模型尚未收敛时,增加训练轮数可以降低测试损失。当训练轮数合适时,测试损失会逐渐下降并趋于稳定。
训练轮数增加通常会使训练损失逐步下降,直到模型接近收敛为止。当训练轮数合适时,训练损失会趋于稳定。
![图片[9] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693babb7af9c7.png)
较大的批量大小可以加速训练过程并有助于更稳定的梯度更新,进而提高测试准确率。小的批量大小可以提供更多次的梯度更新,但可能导致训练不稳定。当批量大小合适时,测试准确率会逐渐提高并趋于稳定。
![图片[10] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693babccb6f45.png)
批量大小过大会导致测试损失较高,因为大批量训练可能会陷入局部最优。当批量大小合适时,测试损失会逐渐下降并趋于稳定。
较大的批量大小通常会使训练损失平滑且收敛较快,但可能收敛到局部最优解。较小的批量大小则训练损失波动较大。当批量大小合适时,训练损失会逐渐下降并趋于稳定。
![图片[11] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693babf7e5ad4.png)
当学习率合适时,测试准确率会逐渐提高并趋于稳定。
![图片[12] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693bac039086f.png)
当学习率合适时,测试损失会逐渐下降并趋于稳定。
当学习率合适时,训练损失会逐渐下降并趋于稳定。
![图片[13] - AI科研 编程 读书笔记 - 【人工智能】AlexNet文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/12/693bac1cb9d0a.png)
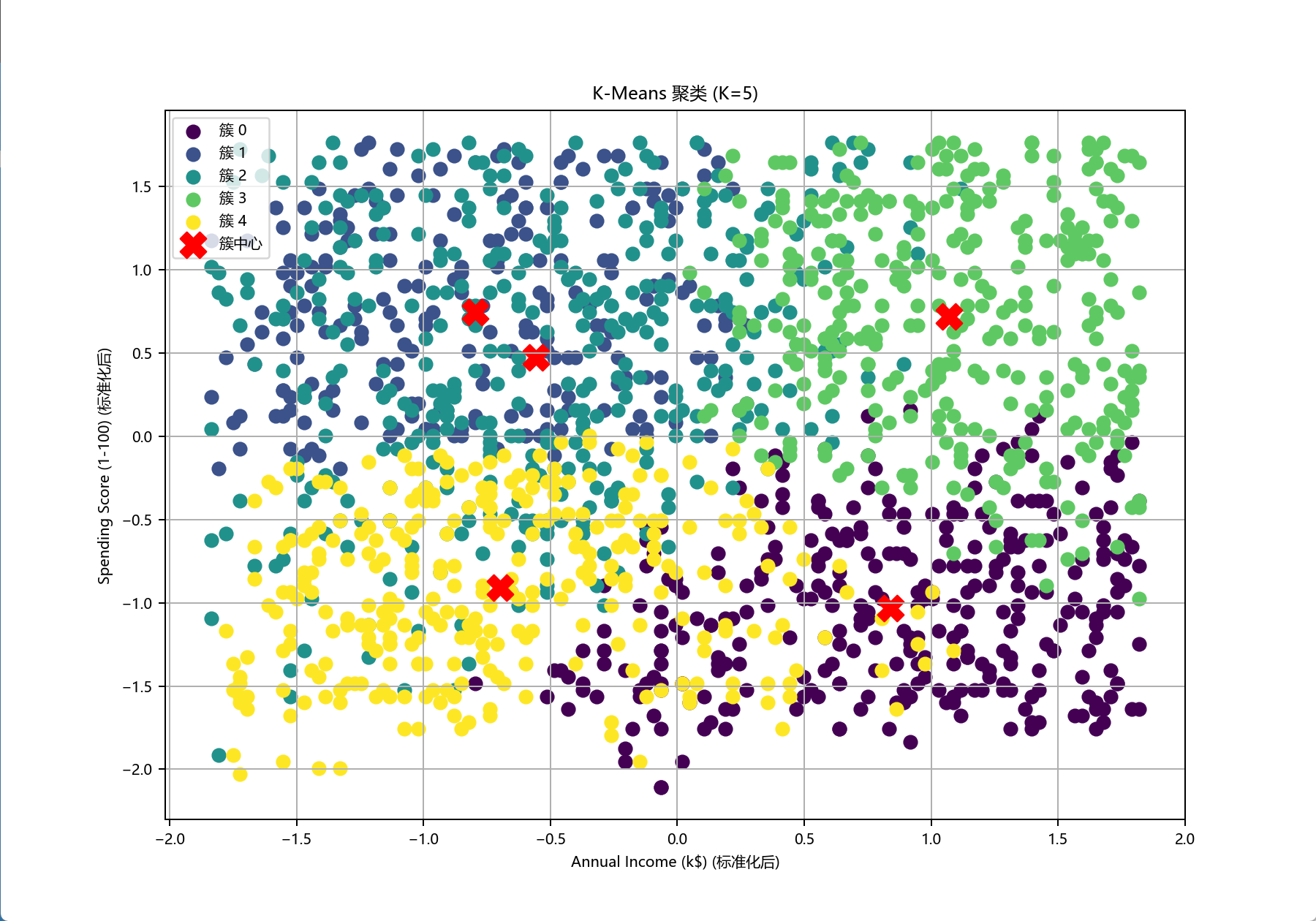
与其他模型的对比
| Model | Test Accuracy | Test Loss | Train Loss |
|---|---|---|---|
| AlexNet | 88.28% | 0.3726 | 13.41 |
| GoogLeNet | 92.19% | 0.6723 | 6.05 |
| VGG | 86.72% | 0.4471 | 8.494 |
| ResNet | 98.44% | 0.2408 | 4.576 |
我将AlexNet与其他经典网络进行跑分对比,以上是我的跑分数据。我训练的AlexNet模型取得了88.28%的测试准确率,性能优于VGG,但与GoogLeNet及ResNet存在差距,特别是ResNet以98.44%的准确率表现最佳。数据显示我的模型训练损失偏高,这表明其收敛性和参数调优方面是未来可以重点改进的方向。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。

























暂无评论内容