

![图片[1] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943bf8280e8d.png)
参考文献:https://arxiv.org/abs/1703.07402
动机
在多目标跟踪领域,Deep SORT 的出现主要源于一个现实问题:传统 SORT 虽然非常快速、易实现,但在遮挡频繁的场景下会出现较多的 ID Switch,这是它的核心短板。
论文的作者希望保持 SORT 的在线、实时和简单的特点,同时显著提升对遮挡的鲁棒性,所以引入了深度学习的外观特征,让关联判断不再只依赖位置与运动,从而补齐 SORT 最致命的缺点。
整个工作保持了工程上的“轻量实用”风格,把复杂度放在离线训练中,而在线阶段保持高效。
所以,这篇论文的核心动机就是:
保持 SORT 的在线、实时和简单的特点,同时显著提升对遮挡的鲁棒性。
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943bfa0d8ec0.png)
创新点
该论文提出的核心方法仍然沿用 tracking-by-detection 的模式和 SORT 的整体结构。轨迹预测部分使用标准的卡尔曼滤波器,状态空间由位置中心点、长宽比、高度及其速度构成(8 维)。轨迹维护规则与 SORT 基本一致,包含轨迹初始化、丢失计数、过期删除等策略,这些简单策略使得整个系统仍旧可以在线实时运行。作者强调,他们使用的是无相机标定、无自运动估计的通用场景,是目前跟踪 benchmark 中最常见的设置,因此方法的鲁棒性需要依赖良好的数据关联机制而非复杂的设计。
对比原版 SORT 只使用 IOU 或马氏距离进行关联,DeepSORT 则将运动距离与外观距离结合。首先仍然计算测量框与预测状态之间的马氏距离,并通过马氏门控剔除不可能的匹配,以避免无效关联。作者指出,马氏距离在目标短时间无遮挡时是有效的,但在长期遮挡或相机运动剧烈时,它会变得不可靠,因此引入第二条分支作为补充。外观分支使用预训练的深度 CNN 提取行人 Re-ID 特征,通过最小余弦距离衡量两者的相似度,同样加入门控以约束匹配可行性。最终关联代价是两项的加权和,可以通过超参数控制两者权重。
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943c00387679.png)
在关联策略上,作者提出了一个 matching cascade 的机制,以轨迹“年龄”为优先级,先为那些最近被观测过的轨迹分配检测,再处理长时间未更新的轨迹。这一策略是为了解决卡尔曼预测方差在长期未观测情况下会变大的问题。如果直接在 Hungarian 中使用所有轨迹,预测不确定度大的轨迹反而更可能匹配到检测点,这是一种反直觉且会导致轨迹漂移与碎片化的现象。Cascade 通过按年龄优先级逐层匹配,强制“新鲜轨迹”在关联中占优势,以提高稳定性。
外观网络部分则是论文的亮点所在。作者使用基于 Wide Residual Network 的 CNN,在大规模行人 Re-ID 数据集上离线训练,最终输出 128 维单位化向量作为表观特征。由于 Re-ID 数据量大、类别丰富,这类特征天然适合用于跨摄像头身份保持。网络本身并不复杂,大约 2.8M 参数,单次前向传播 32 个框大约需 30ms(GTX1050),计算负担较轻,因此适合在实时系统中部署。
实验结果和对比算法
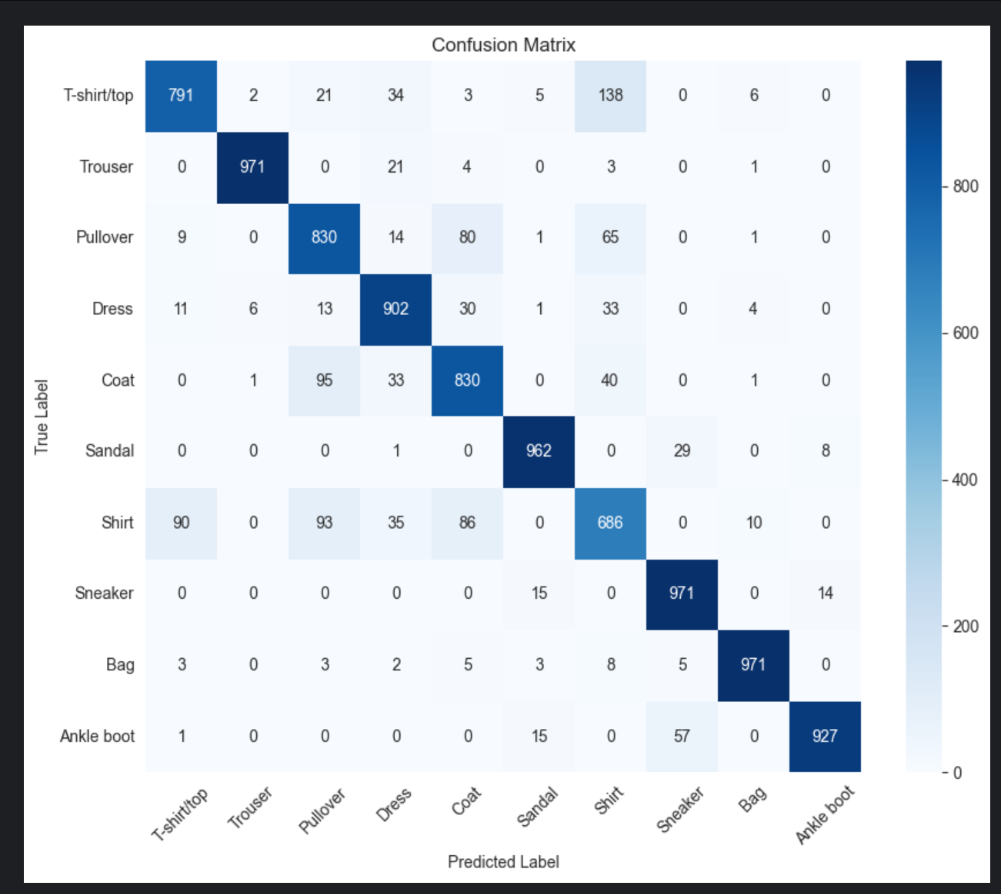
在实验部分,作者将 Deep SORT 与大量 batch 模式和 online 模式的经典算法在 MOT16 benchmark 上进行对比。与原始 SORT 相比,最显著的提升是 ID Switch 从 1423 降到 781,减少约 45%,这几乎是该论文的核心贡献。而 MOTA 稍有提升但不显著,因为作者指出 false positive 由于 detector 的特性和 track age 较大导致更多静态噪声连入轨迹,影响了最终分数。然而从 tracking 体验和可视化结果来看,轨迹变得更加稳定、连贯,遮挡恢复能力强,这是实际应用中非常关键的一点。在与其他 online tracking 方法对比时,Deep SORT 的 ID Switch 数量是最少的,说明其表观表征能力在在线场景极具优势。系统整体运行速度约 20 Hz,其中近一半时间用于外观特征提取,说明 feature extractor 是主要耗时模块。
论文在 Related Work 中把方法放置在 tracking-by-detection 的框架内,与 batch 优化类(如 flow networks、CRF 模型、K-shortest paths)和传统 MHT、JPDAF 做了区分。Deep SORT 更强调在线实时场景,因此方法不依赖全局优化,也不追求复杂建模。与 POI、EAMTT 等在线方法的对比中,Deep SORT 在保持高速度的同时减少了大量 ID Switch,是一种“有效工程优化”的路线。可以说,它不是提出了一种新的理论,而是提出了一种工业级的组合方案,将 Re-ID 和在线 tracking 结合得恰到好处。
![图片[4] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943c084a52cc.png)
模型的局限性
论文提到了一些隐含的问题。例如,检测器误报会直接影响 MOTA,尤其是在静态场景中的虚假响应,较大的最大轨迹年龄会把它们连成无意义的长轨迹。此外,外观特征完全依赖 Re-ID 训练集,如果使用场景不在行人领域,效果可能显著下降。再者,Deep SORT 的表观向量是静态的,没有加入时序表观建模,因此在遮挡极长或外观剧烈变化时仍然可能失败。
未来改进方向
从论文的内容和我的理解来看,大致可以分为几类:
① detector 的升级。由于整个框架基于 tracking-by-detection,检测器的 FP/FN 对最终结果影响极大,因此使用更高质量的检测模型会显著提升效果。
②表观特征可进一步结合视频特征。如 3D CNN、Transformer 或时序特征聚合,从而在遮挡时提供更稳健的身份表示。
③将匹配过程改为学习式。例如使用深度关联网络、图模型或 end-to-end differentiable tracker,使关联策略不再依赖手工设计。
④相机运动与场景建模。如果能够补偿背景运动(如利用光流),运动预测会更可靠,减少 Mahalanobis 的误导。
模型复现和分析
![图片[5] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943c0bfca930.png)
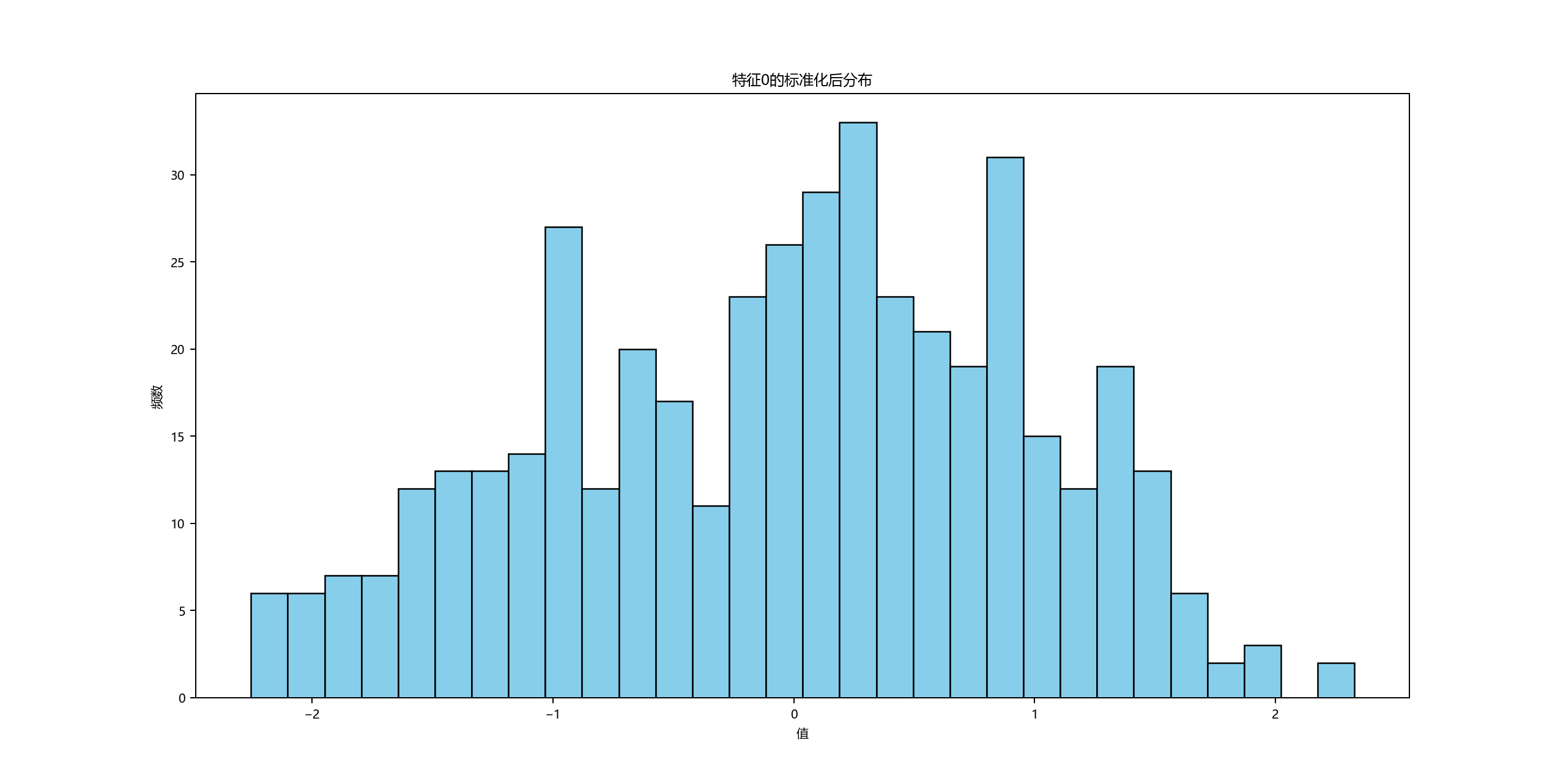
使用MOT16数据集复现
![图片[6] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943c0cf8deb4.png)
模型微调训练(微调YOLOv8-Large)
![图片[7] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943c0f40291e.png)
测试结果(txt)
![图片[8] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943c0fe4a361.png)
测试结果(视频)
![图片[9] - AI科研 编程 读书笔记 - 【人工智能】DeepSort文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/18/6943c111bb1a6.png)
与其他模型的对比表
| 模型 | 类型 | 核心创新点 | MOTA | ID Switch | 速度 |
|---|---|---|---|---|---|
| SORT | 在线 | 仅使用运动信息与 IOU 进行关联,结构极简 | 59.8 | 1423 | 60 Hz |
| Deep SORT | 在线 | 引入深度外观特征,采用马氏距离与余弦距离双门控,并使用级联匹配 | 61.4 | 781 | 40 Hz |
| POI | 在线 | 强检测器结合高性能外观特征,外观建模较为复杂 | 66.1 | 805 | 10 Hz |
| EAMTT | 在线 | 结合弱检测与强检测,采用特征融合策略 | 52.5 | 910 | 12 Hz |
| KDNT(batch) | 批处理 | 基于深度网络的全局数据关联方法 | 68.2 | 933 | 0.7 Hz |
| LMP(batch) | 批处理 | 采用多割(multi-cut)图优化,同时进行分割与轨迹关联 | 71.0 | 434 | 0.5 Hz |
| NOMT(batch) | 近在线 | 融合多视角局部流特征,并采用轨迹聚合策略 | 62.2 | 406 | 3 Hz |
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。























暂无评论内容