

![图片[1] - AI科研 编程 读书笔记 - 【人工智能】OpenPose文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/16/6940c6488f164.png)
参考文献:https://ieeexplore.ieee.org/abstract/document/8765346(TPAMI 2021)
动机
在多人姿态估计领域,主要存在两种主流思路。一种是自顶向下(Top-down)的方法,即先使用检测器找出图像中的每个人,然后对每个检测框进行单人姿态估计。这种方法的缺陷在于其推理时间与图像中的人数成正比,计算复杂度为O(N),当人群密集时,速度会显著下降,且严重依赖于人体检测器的准确性,一旦检测器失效(如拥挤场景),姿态估计也无从谈起。另一种是自底向上(Bottom-up)的方法,先检测出所有的人体关节点,再将它们组装成个体。早期的自底向上方法(如DeepCut)虽然规避了检测器依赖,但其关节点聚类过程通常基于复杂的图论优化,计算成本极高,处理单张图片甚至需要数分钟。
所以,这篇论文的核心动机就是:
设计一种既能保持高精度,又能实现实时推理,且计算时间不随人数线性增长的自底向上算法。
创新点
这篇论文提出的核心方法是部分亲和场(Part Affinity Fields, PAFs)。这是一个非参数化的表示方法,用于通过“联结”来组装检测到的身体部位。传统方法在关联两个关节点(如手肘和手腕)时,往往只考虑位置信息或中点信息,这在多人肢体重叠时容易产生错误的连接。PAFs本质上是一个2D向量场,它不仅对肢体的位置进行编码,还显式地编码了肢体的方向信息。通过在候选关节点之间计算PAFs的线积分,网络可以有效衡量两个部位属于同一个人的置信度。在架构设计上,作者采用了一个多阶段的CNN网络,同时预测关节点的置信度图(Confidence Maps)和PAFs。与会议版本相比,期刊版本的一个重要改进是:作者通过实验证明,PAFs的精细化(Refinement)对于结果至关重要,而关节点位置的精细化则相对次要。因此,新模型去除了后续阶段中对置信度图的重复精细化,只保留对PAFs的迭代优化,并加深了网络深度。这种设计不仅将运算速度提升了约2倍,还使准确率提升了约7%。最后,利用贪婪算法(Greedy Parsing)基于二分图匹配(Bipartite Matching)将这些局部连接组装成完整的人体骨架,这一过程极其高效,相比于复杂的全局图优化,仅仅损失了极微小的精度,但换来了实时性能。
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】OpenPose文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/16/6940c73a0d7f6.png)
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】OpenPose文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/16/6940c74b99e45.png)
数据集
数据集方面,除了使用标准的MPII和COCO数据集外,该工作的一个重要贡献是发布了一个包含1.5万个标注实例的脚部数据集(Foot Dataset)。由于COCO和MPII通常只标注到脚踝,缺乏脚趾和脚跟的信息,这在3D建模或VR应用中会导致“糖纸效应”或模型陷入地面的问题。作者证明,通过联合训练身体和脚部关键点,不仅能获得更精细的足部姿态,还能反过来辅助提升腿部关键点(如脚踝)的预测准确率。
实验结果和对比算法
在实验结果与对比算法方面,OpenPose在MPII和COCO两大基准数据集上均取得了极具竞争力的成绩。
在MPII数据集上,该方法大幅超越了之前的自底向上方法(如DeepCut),在全测试集上达到了75.6%的mAP。在COCO关键点挑战赛中,虽然OpenPose的精度略低于一些极度复杂的自顶向下方法(如AlphaPose或Mask R-CNN),但其在速度与精度的权衡上具有显著优势。
特别是在推理速度分析上,论文展示了OpenPose的运行时间是常数级的O(1),与图像中的人数无关;相比之下,Mask R-CNN和AlphaPose的运行时间随人数线性增长。在GTX 1080 Ti上,OpenPose能达到约22 FPS的实时帧率14。此外,论文还展示了该方法在车辆关键点估计上的通用性。
与其他模型的对比
当前模型与其他模型的对比,主要体现在逻辑和架构的取舍上。相比于DeepCut等基于整数线性规划(ILP)的早期自底向上方法,OpenPose通过将NP-hard的图匹配问题松弛为简单的二分图匹配,解决了计算瓶颈。相比于Mask R-CNN等自顶向下方法,OpenPose虽然在单人精度上可能略逊一筹(主要是受限于输入图像的全局分辨率,而自顶向下方法可以对每个检测框进行缩放裁剪),但它避免了“早期承诺”问题,即不会因为漏检人而直接丢失姿态,并且在拥挤场景下的推理延迟极低。
未来改进方向
1.对于非常规姿态(如倒立)或极度罕见的视角,模型容易失效,这可以通过数据增强部分缓解,但会导致整体精度下降。
2.在极度拥挤的场景中,不同人的PAFs可能会发生重叠,导致贪婪解析算法将属于不同人的身体部位错误地合并在一起。
3.雕像或动物有时会被误检为人类,这表明网络需要更多的负样本训练来区分“类人”物体。
未来的改进方向可能包括引入更高分辨率的处理以缩小与自顶向下方法的精度差距,以及探索更优的解析算法来处理重叠场的问题。
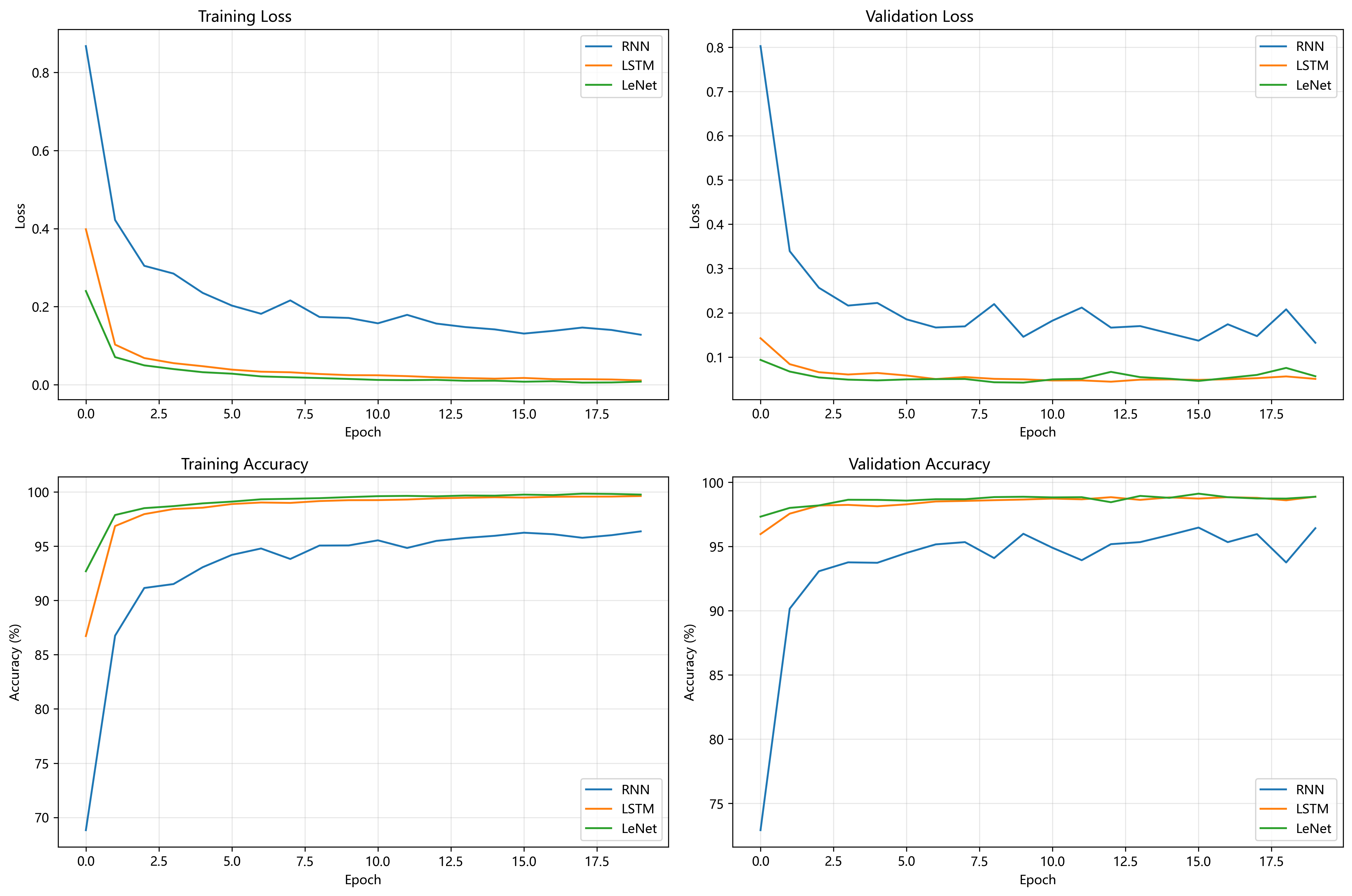
模型复现和分析
![图片[4] - AI科研 编程 读书笔记 - 【人工智能】OpenPose文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/16/6940c91dc1b2d.png)
使用MPII数据集复现
![图片[5] - AI科研 编程 读书笔记 - 【人工智能】OpenPose文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/16/6940c932e1f41.png)
数据预处理
![图片[6] - AI科研 编程 读书笔记 - 【人工智能】OpenPose文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/16/6940c93e983e9.png)
训练完成
![图片[7] - AI科研 编程 读书笔记 - 【人工智能】OpenPose文献阅读及源码复现 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/12/16/6940c94d87a85.png)
与其他模型的对比表
| 模型名称 | 方法类型 | 核心创新点 / 技术原理 | 复杂度与速度 | 精度表现(COCO AP / MPII mAP) |
|---|---|---|---|---|
| OpenPose | 自底向上 | 部分亲和场(PAFs):使用非参数化的二维向量场编码肢体位置与方向, 并通过贪婪解析算法进行二分图匹配。 | O(1):推理时间不随人数增加而增加。 在 GTX 1080 Ti 上约 22 FPS,适合实时应用。 |
COCO:64.2%(Test-dev) MPII:75.6%(Full set) |
| Mask R-CNN | 自顶向下 | ROI Align:先进行高精度人体检测,再对每个检测框进行关键点预测, 依托强大的实例分割能力。 | O(N):速度与人数成正比,人数较多时推理速度显著下降。 | COCO:69.2% |
| AlphaPose | 自顶向下 | RMPE:通过 STN(空间变换网络)与姿态引导的 NMS, 缓解检测框不准确对单人姿态估计的影响。 | O(N):依赖检测器生成的候选框数量, 在拥挤场景下推理较慢。 | COCO:71.0% |
| DeeperCut | 自底向上 | 图论优化:基于图像相关的成对评分, 使用整数线性规划(ILP)求解全连接图。 | 极慢:单张图像处理时间可达数分钟(如约 485 秒), 计算成本极高,无法实时应用。 | MPII:59.5% |
| PersonLab | 自底向上 | 几何嵌入方法:预测关键点热图及短距离/中距离位移, 并通过 Hough 投票进行聚类。 | 慢于 OpenPose:为追求高精度而牺牲速度, 未以实时性能为主要目标。 | COCO:68.7% |
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。

























暂无评论内容