

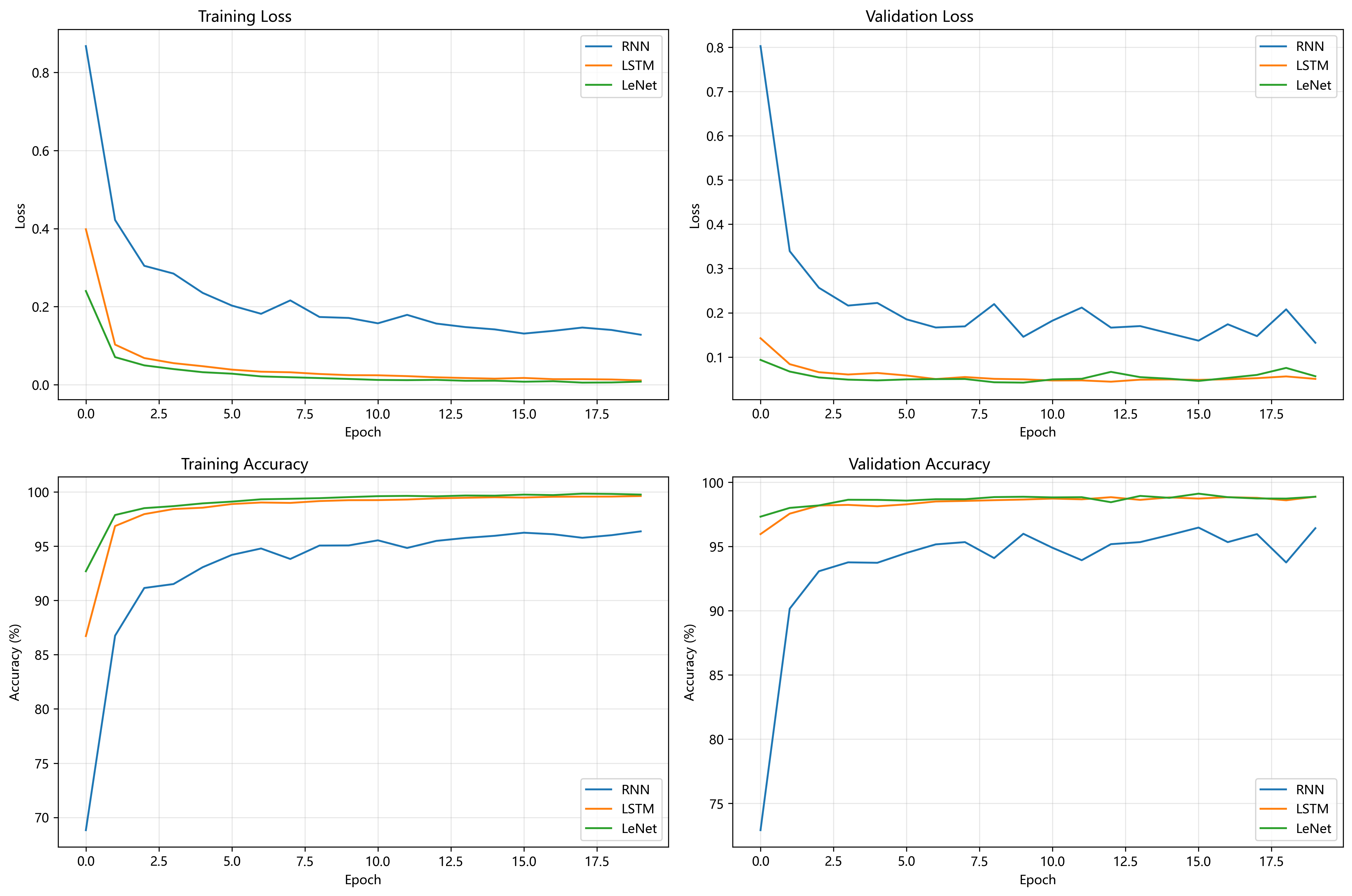
我对比了K-Means、DBSCAN和层次聚类三种算法在客户细分数据集上的表现。K-Means通过肘部法确定最佳K值为5,轮廓系数0.2332表现最好;DBSCAN对参数敏感仅形成2个簇;层次聚类使用余弦距离和平均连接,性能介于两者之间。最终K-Means的聚类结果被用于制定针对不同客户群体的营销策略。
描述算法、数据集、及所设计的实验方案
算法描述
在这次实验中,我对比了三种经典的聚类算法在客户细分数据集上的表现。我选择的算法分别是kmeans、DBSCAN、层次聚类。
首先来说kmeans算法是一种基于划分的聚类方法。它的核心思想是迭代地将数据点分配给最近的簇中心,并重新计算簇中心,直到簇的分配不再发生显著变化或达到预设的迭代次数。该算法的关键参数是簇的数量k。在实验中,我计划通过肘部法观察簇内平方和(惯性)随K值变化的趋势,并结合轮廓系数来辅助确定一个较为合适的K值。
然后关于DBSCAN算法,它是一种基于密度的聚类方法。它能够发现任意形状的簇,并且能有效地识别出噪声点。DBSCAN的主要参数是邻域半径eps和形成核心对象所需的最小样本数min_samples。我打算通过网格搜索的方式,结合轮廓系数来寻找这两个参数的最佳组合,来达到较好的聚类效果。
层次聚类算法(我这里具体使用的是AgglomerativeClustering)是一种自底向上的聚类方法。它初始时将每个样本点视为一个独立的簇,然后迭代地合并最相似的簇,直到达到预设的簇数量或者所有点都合并为一个簇。此算法的关键参数包括距离度量方法(如欧氏距离、余弦距离)和簇间连接方式(如Ward、Average、Complete)。我计划尝试不同的距离度量和连接方式组合,并参考kmeans选定的簇数量,来评估其性能。对于Ward连接方式,它通常与欧氏距离配合使用。我还会利用谱系图来直观地观察数据点的合并过程,尤其是在低维数据上,这有助于理解簇的形成。
对于这三种算法,我都将采用轮廓系数和Calinski-Harabasz指数作为主要的模型性能度量指标。
描述数据集
我选用了一个公开的客户细分数据集,该数据集来源于Kaggle平台(https://www.kaggle.com/datasets/govindkrishnadas/segment),这个数据集用来通过客户的各项特征来进行市场细分,以便进行更精准的营销。
原始数据集包含1599条客户记录,共有5个特征。这些特征分别是:
CustomerID:客户的唯一标识符。在我的分析中,这是一个无关特征,因此我会提前将其移除。
Gender:客户的性别。
Age:客户的年龄。
AnnualIncome(k$):客户的年收入。
SpendingScore(1-100):客户的消费指数。
从后续程序输出可知,数据集非常完整,所有特征均没有缺失值。描述性统计结果显示,例如客户平均年龄约为47岁,平均年收入约为80k美刀,平均消费得分约为55。
在数据预处理阶段,我首先移除了CustomerID列。接着,我对分类特征Gender进行了独热编码(One-HotEncoding),并设置drop=’first’以避免多重共线性,编码后男性为1,女性为0。对于数值特征Age、AnnualIncome(k$)和SpendingScore(1-100),我采用了Z-score标准化处理,使它们转换成均值为0、标准差为1的分布,这样做有助于消除不同特征尺度差异对聚类算法(尤其是基于距离度量的算法如K-Means和层次聚类)的影响。我还通过绘制直方图观察了年收入和消费得分在标准化前后的分布情况。
实验方案
首先,在数据准备阶段,在程序中打开选择的客户细分数据集。紧接着进行数据预处理(移除对聚类无意义的CustomerID特征;对Gender这样的分类特征进行独热编码;对Age、AnnualIncome(k$)和SpendingScore(1-100)这些数值特征进行Z-score标准化)。
完成预处理后,分析关键特征(如年收入和消费得分)在原始数据和标准化后的数据中的分布情况,以更好地理解数据特性。
其次,进入模型训练与调参阶段。我会分别实现K-Means、DBSCAN和层次聚类三种算法。
对于K-Means,我会设定一个K值的范围(例如从2到10),计算每个K值下的模型惯性(inertia)和轮廓系数,通过绘制“手肘图”和轮廓系数图来辅助选择一个最佳的K值。
对于DBSCAN,我会设定一个参数网格,包含不同的eps(邻域半径)和min_samples(最小样本数)组合。然后,我会进行网格搜索,以轮廓系数为主要评价指标,找到最优的参数配置。
对于层次聚类,我会首先尝试使用选择的两个关键特征(如标准化后的年收入和消费得分)绘制谱系图,以直观感受簇的形成过程。然后,我会固定簇的数量(可以参考K-Means的最佳K值),并尝试不同的距离度量(如欧氏距离、余弦距离)和连接方式(如Ward、Average、Complete)的组合,同样以轮廓系数为优化目标。特别注意,Ward连接方式只适用于欧氏距离。
再次,在模型性能度量阶段,对于每种算法在最佳参数组合下得到的聚类结果,我都会计算并输出轮廓系数和Calinski-Harabasz指数。这两个指标将用于横向对比不同算法的聚类性能。我还会记录下每种算法最终形成的簇的数量。
然后,在可视化阶段,我会选择两个重要的特征(例如标准化后的“年收入”和“消费得分”),将这三种算法的聚类结果进行二维可视化。对于K-Means,我还会特别标出簇中心的位置。对于DBSCAN,我会区分显示不同的簇以及可能的噪声点。
最后,作为进阶要求,如果聚类效果理想(特别是K-Means的结果),我会将得到的簇标签合并回原始数据。然后,我会计算每个簇中各个特征(如年龄、年收入、消费得分、性别分布)的均值或分布情况,基于这些分析,尝试为识别出的不同客户群体提出初步的、有针对性的营销策略建议。整个实验过程的输出,包括数据摘要、参数选择过程、性能指标和可视化图表,都会被清晰记录。
实验详细操作步骤或程序清单
实验结果(上传实验结果截图或者简单文字描述)
![图片[1] - AI科研 编程 读书笔记 - 【人工智能】【Python】聚类算法实验(K-Means/DBSCAN/层次聚类) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/10/681ef93459fae.png)
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】【Python】聚类算法实验(K-Means/DBSCAN/层次聚类) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/10/681ef944881c8.png)
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】【Python】聚类算法实验(K-Means/DBSCAN/层次聚类) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/10/681ef95320be3.png)
![图片[4] - AI科研 编程 读书笔记 - 【人工智能】【Python】聚类算法实验(K-Means/DBSCAN/层次聚类) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/10/681ef96219aef.png)
![图片[5] - AI科研 编程 读书笔记 - 【人工智能】【Python】聚类算法实验(K-Means/DBSCAN/层次聚类) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/10/681ef97138815.png)
![图片[6] - AI科研 编程 读书笔记 - 【人工智能】【Python】聚类算法实验(K-Means/DBSCAN/层次聚类) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/10/681ef981f0359.png)
![图片[7] - AI科研 编程 读书笔记 - 【人工智能】【Python】聚类算法实验(K-Means/DBSCAN/层次聚类) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/10/681ef990b8c5b.png)
下面是控制台输出
D:\AnacondaEnvs\PyTorch\python.exe D:\桌面\编程相关\04_IDE练习项目\sklearn\scikit-learn\Lab\lab05.py
— 原始数据 —
CustomerID Gender Age Annual Income (k$) Spending Score (1-100)
0 1 Male 19 15 39
1 2 Male 21 15 81
2 3 Female 20 16 6
3 4 Female 23 16 77
4 5 Female 31 17 40— 数据信息 —
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 1599 entries, 0 to 1598
Data columns (total 5 columns):
# Column Non-Null Count Dtype
— —— ————– —–
0 CustomerID 1599 non-null int64
1 Gender 1599 non-null object
2 Age 1599 non-null int64
3 Annual Income (k$) 1599 non-null int64
4 Spending Score (1-100) 1599 non-null int64
dtypes: int64(4), object(1)
memory usage: 62.6+ KB
可以看到全部都是1599个非空值,证明数据集完整无误— 描述性统计 —
包括计数、平均值、标准差、最小值、25%分位数、中位数、75%分位数和最大值等统计指标:
CustomerID Age Annual Income (k$) Spending Score (1-100)
count 1599.000000 1599.000000 1599.000000 1599.000000
mean 800.000000 46.944966 80.292683 54.918074
std 461.735855 14.207764 35.605253 25.567113
min 1.000000 18.000000 15.000000 1.000000
25% 400.500000 35.000000 50.500000 34.000000
50% 800.000000 46.000000 78.000000 55.000000
75% 1199.500000 59.000000 110.000000 76.000000
max 1599.000000 78.000000 145.000000 100.000000— 数据预处理 —
— 预处理后的数据 (前5行) —
Gender_Male Age Annual Income (k$) Spending Score (1-100)
0 1.0 -1.967495 -1.834367 -0.622794
1 1.0 -1.826683 -1.834367 1.020455
2 0.0 -1.897089 -1.806273 -1.913919
3 0.0 -1.685871 -1.806273 0.863955
4 0.0 -1.122622 -1.778178 -0.583669用于可视化的特征在 X_processed 中的索引: 2, 3
用于可视化的特征在 X_visualize 中的形状: (1599, 2)— K-Means 聚类 —
选择的最佳 K 值 (示例): 5
— K-Means (K=5) —
簇的数量: 5
轮廓系数: 0.2332
Calinski-Harabasz 指数: 508.19— DBSCAN 聚类 —
DBSCAN 网格搜索调参 (基于轮廓系数):
eps=0.3, min_samples=3 -> 簇数: 93, 噪声点数: 392
轮廓系数: -0.3405
eps=0.3, min_samples=5 -> 簇数: 57, 噪声点数: 835
轮廓系数: -0.3019
eps=0.3, min_samples=7 -> 簇数: 33, 噪声点数: 1259
轮廓系数: -0.3944
eps=0.3, min_samples=10 -> 簇数: 3, 噪声点数: 1569
轮廓系数: -0.3062
eps=0.5, min_samples=3 -> 簇数: 5, 噪声点数: 26
轮廓系数: -0.1675
eps=0.5, min_samples=5 -> 簇数: 5, 噪声点数: 81
轮廓系数: -0.1336
eps=0.5, min_samples=7 -> 簇数: 10, 噪声点数: 177
轮廓系数: -0.2945
eps=0.5, min_samples=10 -> 簇数: 4, 噪声点数: 341
轮廓系数: -0.1750
eps=0.7, min_samples=3 -> 簇数: 2, 噪声点数: 2
轮廓系数: 0.0835
eps=0.7, min_samples=5 -> 簇数: 2, 噪声点数: 3
轮廓系数: 0.0744
eps=0.7, min_samples=7 -> 簇数: 2, 噪声点数: 3
轮廓系数: 0.0744
eps=0.7, min_samples=10 -> 簇数: 2, 噪声点数: 16
轮廓系数: 0.0747
eps=1.0, min_samples=3 -> 簇数: 2, 噪声点数: 0
轮廓系数: 0.0961
eps=1.0, min_samples=5 -> 簇数: 2, 噪声点数: 0
轮廓系数: 0.0961
eps=1.0, min_samples=7 -> 簇数: 2, 噪声点数: 0
轮廓系数: 0.0961
eps=1.0, min_samples=10 -> 簇数: 2, 噪声点数: 0
轮廓系数: 0.0961
DBSCAN 最佳参数: {‘eps’: 1.0, ‘min_samples’: 3}
— DBSCAN (eps=1.0, min_samples=3) —
簇的数量: 2
轮廓系数: 0.0961
Calinski-Harabasz 指数: 109.74— 层次聚类 —
层次聚类调参 (固定簇数 n_clusters=5):
尝试: affinity=’euclidean’, linkage=’ward’
轮廓系数: 0.1905
尝试: affinity=’euclidean’, linkage=’average’
轮廓系数: 0.1947
尝试: affinity=’euclidean’, linkage=’complete’
轮廓系数: 0.1513
跳过: linkage=’ward’ 仅支持 affinity=’euclidean’. 当前 affinity=’cosine’
尝试: affinity=’cosine’, linkage=’average’
轮廓系数: 0.2072
尝试: affinity=’cosine’, linkage=’complete’
轮廓系数: 0.1628
层次聚类最佳参数: {‘affinity’: ‘cosine’, ‘linkage’: ‘average’, ‘n_clusters’: 5}
— 层次聚类 (cosine, average, K=5) —
簇的数量: 5
轮廓系数: 0.2072
Calinski-Harabasz 指数: 465.04— 模型性能总结 (基于轮廓系数和Calinski-Harabasz指数) —
— K-Means (K=5) —
簇的数量: 5
轮廓系数: 0.2332
Calinski-Harabasz 指数: 508.19
— DBSCAN (eps=1.0, min_samples=3) —
簇的数量: 2
轮廓系数: 0.0961
Calinski-Harabasz 指数: 109.74
— 层次聚类 (cosine, average, K=5) —
簇的数量: 5
轮廓系数: 0.2072
Calinski-Harabasz 指数: 465.04— 性能对比表格 —
算法 参数 轮廓系数 Calinski-Harabasz指数 簇数量
0 K-Means K=5 0.233203 508.185892 5
1 DBSCAN eps=1.0, min_samples=3 0.096077 109.742935 2
2 层次聚类 affinity=cosine, linkage=average, K=5 0.207192 465.035114 5— 针对不同群体的营销策略 (基于K-Means K=5 示例) —
K-Means 各簇特征均值及性别分布:
Age Annual Income (k$) Spending Score (1-100) Female Male
Cluster_KMeans
0 40.920635 110.161905 28.577778 0.263492 0.736508
1 58.489451 51.936709 74.016878 0.202532 0.797468
2 32.156566 60.464646 67.030303 0.335859 0.664141
3 52.808260 118.353982 73.289086 0.294985 0.705015
4 56.657051 55.487179 31.669872 0.310897 0.689103— 营销策略建议 (基于K-Means 各簇特征分析) —
— 簇 0 —
平均年龄: 40.9
平均年收入 (k$): 110.2
平均消费得分: 28.6
(性别分布: Female: 26.3%, Male: 73.7%)
特征: 高收入,低消费
营销策略: 了解消费顾虑,强调产品性价比和长期价值,推送高价值或投资类商品信息,提供专属折扣或会员权益。
——————–— 簇 1 —
平均年龄: 58.5
平均年收入 (k$): 51.9
平均消费得分: 74.0
(性别分布: Female: 20.3%, Male: 79.7%)
特征: 低收入,高消费
营销策略: 推广时尚、潮流商品、限时促销、社交媒体互动营销、提供灵活支付选项(如分期付款)。
——————–— 簇 2 —
平均年龄: 32.2
平均年收入 (k$): 60.5
平均消费得分: 67.0
(性别分布: Female: 33.6%, Male: 66.4%)
特征: 低收入,高消费
营销策略: 推广时尚、潮流商品、限时促销、社交媒体互动营销、提供灵活支付选项(如分期付款)。
——————–— 簇 3 —
平均年龄: 52.8
平均年收入 (k$): 118.4
平均消费得分: 73.3
(性别分布: Female: 29.5%, Male: 70.5%)
特征: 高收入,高消费
营销策略: 提供VIP服务、新品优先体验、高端产品推荐、个性化定制优惠、建立品牌忠诚度计划。
——————–— 簇 4 —
平均年龄: 56.7
平均年收入 (k$): 55.5
平均消费得分: 31.7
(性别分布: Female: 31.1%, Male: 68.9%)
特征: 低收入,低消费
营销策略: 专注于基本款、性价比商品,强调促销信息、折扣券、低价入门级产品,引导性消费。
——————–进程已结束,退出代码为 0
下面是结果分析
K-Means算法
通过肘部法和轮廓系数确定最佳簇数量K值为5。在性能指标上,轮廓系数为0.2332,Calinski-Harabasz指数为508.19。在本次实验中,K-Means (K=5) 的表现最为出色,获得了最高的轮廓系数和Calinski-Harabasz指数,这表明其聚类效果较好,簇内数据点紧密,簇间分离度高。其划分出的5个簇被用于后续营销策略分析,从业务角度来看具有一定的解释性和实用性。不过,0.2332的轮廓系数距离理想值1还有差距,意味着数据集中客户群体之间存在一定重叠,簇的边界不够清晰。
DBSCAN算法
经网格搜索,选定最佳参数为eps=1.0(邻域半径)和min_samples=3(最小样本数)。其性能指标为轮廓系数0.0961,Calinski-Harabasz指数109.74。相比K-Means和层次聚类,DBSCAN的表现明显较差,各项指标均远低于其他两种算法。最终仅形成2个簇,对于客户细分任务来说,这样的结果过于粗略,难以提供有价值的客户洞察。从网格搜索过程可以看出,DBSCAN对参数eps和min_samples极为敏感,不同参数组合下,簇数量和噪声点数量波动很大。这可能是因为数据本身密度分布不均匀,导致DBSCAN发现任意形状簇和处理噪声的优势未能有效发挥。
层次聚类算法(Agglomerative Clustering)
在固定簇数量为5(与K-Means一致便于比较)的情况下,通过网格搜索得到最佳参数组合为affinity=’cosine’(余弦距离)和linkage=’average’(平均连接)。其轮廓系数为0.2072,Calinski-Harabasz指数为465.04 。性能介于K-Means和DBSCAN之间,虽优于DBSCAN,但略逊于K-Means。选择余弦距离作为最佳亲和度量,说明在该数据集中,样本点在高维空间中的方向性对区分簇更为关键。而平均连接方法考虑了簇间所有点对的平均距离,成为最佳选择。
总结与对比
整体来看,基于轮廓系数和Calinski-Harabasz指数,K-Means (K=5) 在本次实验的聚类效果最佳,数值指标领先,且聚类结果适用于后续营销策略制定。在实用性与解释性方面,K-Means划分的群体特征清晰,便于理解和应用;层次聚类同样产生5个簇,性能尚可,可作为备选方案;DBSCAN的2个簇结果则过于笼统。
从算法特性分析,K-Means简单高效,适合球状簇,但需预先指定K值;DBSCAN能发现任意形状的簇且无需预设簇数,但对参数敏感,在密度差异大的数据集中表现不佳;层次聚类可提供不同粒度的聚类结果,无需预设簇数(实验中为比较而指定除外),虽然计算复杂度较高,但在本次数据集规模下影响不大。
此外,所有算法的轮廓系数都不算高,最高约0.23,这反映出该数据集本身的结构特点,使得清晰的客户分群存在一定难度,不同群体间可能存在较多特征重叠。
对于本次客户细分数据集和实验设置,K-Means算法在K=5时聚类性能最优,具有较好的业务解释潜力;层次聚类次之;而DBSCAN在当前参数调优下,未能有效细分客户群体 。
疑难小结(总结个人在实验中遇到的问题或者心得体会)
完成了本次聚类算法实验后我收获很多。在数据预处理阶段,标准化与编码操作让我认识到数据格式规范对算法效果的关键影响。在算法实践中,kmeans通过手肘法和轮廓系数确定K值,让我印象深刻,最终聚类效果最佳。DBSCAN 对参数极为敏感,本次实验因数据密度不均未取得理想效果。层次聚类的谱系图可视化很有启发性,但其计算复杂度较高。
实验中也遇到不少问题。参数调优时,K值选择缺乏明确标准,DBSCAN和层次聚类网格搜索耗时久。同时,还遭遇了scikit-learn爆出的一些警告,通过查阅资料得知不影响实验结果,所以忽略了警告。这次实验让我明白,算法选择需贴合数据特性,实践中要多尝试、多总结,才能提升数据分析能力。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。

























暂无评论内容