

我使用支持向量机(SVM)算法在两类数据集上进行分类实验,对比了线性核、多项式核和RBF核的表现。实验结果表明,在线性可分数据集上三种核函数都能达到100%准确率,但在非线性可分数据集上RBF核表现最佳(96%准确率),而线性核和多项式核效果较差。通过SMOTE过采样处理类别不平衡问题,并实现了决策边界的可视化分析。
描述算法、数据集、及所设计的实验方案
这次实验使用支持向量机SVM算法,通过不同核函数(线性核、多项式核、径向基核RBF)在两类数据集上进行分类实验。为了解决非线性可分问题,SVM引入了核函数将数据映射到更高维的特征空间,从而在该高维的空间中寻找线性可分的超平面来解决这个分类问题。
实验中我用了两种不同类型的人工合成数据集,来对比线性可分与非线性可分数据对SVM表现的影响。第一个数据集由make_blobs函数生成,一共有500个样本,两个特征,两个类别,样本分布在两个高斯簇中,适用于线性可分问题。然后第二个数据集由make_circles函数生成,一样有500个样本、两个特征、两个类别,样本呈环状分布,是非线性可分的问题。两个数据集的特征均为二维空间中的坐标点,标签为0或者1,代表所属类别。
实验方案分为多个步骤:首先我对数据集进行描述和分析,包括样本数量、特征数量和类别分布;随后我将数据划分为训练集和测试集,并对特征进行标准化处理。针对不同核函数的SVM模型,分别构建线性核、多项式核和 RBF 核 SVM,并利用网格搜索进行超参数调优,如惩罚系数C和核函数参数gamma等,以获取最优模型。模型训练完成后,在测试集上评估其性能,输出准确率、混淆矩阵以及分类报告。最后为了提升对模型边界的理解,本实验在二维特征条件下实现了支持向量与决策边界的可视化。
考虑到实际问题中常存在类别不平衡情况,实验中我还引入了SMOTE算法对训练数据进行过采样,以平衡类别数量,验证该处理方式对模型性能的影响。通过对比不同核函数在不同数据分布下的表现,全面分析SVM算法在分类问题中的适用性和效果。
实验详细操作步骤或程序清单
步骤 1:导入必要的库和模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_circles
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from imblearn.over_sampling import SMOTE步骤 2:设置matplotlib字体和显示参数
plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"]
plt.rcParams["figure.dpi"] = 120
plt.rcParams["font.size"] = 8
步骤 3:定义函数用于打印数据集基本信息
def describe_dataset(X, y, name):
print(f"\n数据集:{name}")
print(f"- 样本数量:{X.shape[0]}")
print(f"- 特征数量:{X.shape[1]}")
unique, counts = np.unique(y, return_counts=True)
print(f"- 类别分布:{dict(zip(unique, counts))}")步骤 4:定义函数用于绘制数据分布可视化
def plot_distribution(X, y, title):
plt.figure(figsize=(6, 5))
for label in np.unique(y):
plt.scatter(X[y == label, 0], X[y == label, 1], label=f"类别 {label}")
plt.title(title)
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.legend()
plt.show()步骤 5:定义主实验函数,包含数据处理、模型训练与评估
def experiment_on_dataset(X, y, name):
# 1. 描述数据集
describe_dataset(X, y, name)
# 2. 划分训练/测试集(30% 测试集)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# 3. 非平衡数据处理(SMOTE过采样)
sm = SMOTE(random_state=42)
X_train, y_train = sm.fit_resample(X_train, y_train)
describe_dataset(X_train, y_train, name + "(SMOTE过采样之后)")
# 4. 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 5. 数据分布可视化(训练集)
if X_train_scaled.shape[1] == 2:
plot_distribution(X_train_scaled, y_train, f"{name}(训练集,标准化之后)")
# 6. 定义模型与参数网格
models = {
'linear': SVC(kernel='linear'),
'poly': SVC(kernel='poly', degree=3),
'rbf': SVC(kernel='rbf')
}
param_grids = {
'linear': {'C': [0.1, 1, 10, 100]},
'poly': {'C': [0.1, 1, 10], 'gamma': ['scale', 'auto']},
'rbf': {'C': [0.1, 1, 10], 'gamma': ['scale', 'auto']}
}
# 7. 训练、调参、评估
for kernel_name, model in models.items():
print(f"\n=== {kernel_name} 核 SVM ===")
grid = GridSearchCV(
model, param_grids[kernel_name], cv=5,
scoring='accuracy', n_jobs=-1
)
grid.fit(X_train_scaled, y_train)
print(f"最佳参数:{grid.best_params_}")
best_model = grid.best_estimator_
# 测试集预测
y_pred = best_model.predict(X_test_scaled)
acc = accuracy_score(y_test, y_pred)
print(f"测试集准确率:{acc:.4f}")
# 混淆矩阵和分类报告
cm = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", cm)
print("分类报告:\n", classification_report(y_test, y_pred))
# 决策边界可视化(二维特征)
if X_train.shape[1] == 2:
plot_decision_boundary(best_model, scaler, X_test, y_test, title=f"{name} - {kernel_name} 核的决策边界")步骤 6:定义函数用于绘制 SVM 决策边界
def plot_decision_boundary(model, scaler, X, y, title):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(
np.linspace(x_min, x_max, 300),
np.linspace(y_min, y_max, 300)
)
grid = np.c_[xx.ravel(), yy.ravel()]
grid_scaled = scaler.transform(grid)
Z = model.predict(grid_scaled)
Z = Z.reshape(xx.shape)
plt.figure(figsize=(6, 5))
plt.contourf(xx, yy, Z, alpha=0.2)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k')
plt.title(title)
plt.show()
步骤 7:生成数据集并执行实验
if __name__ == '__main__':
# 数据集 1:线性可分
X1, y1 = make_blobs(
n_samples=500, centers=2, n_features=2,
cluster_std=1.0, random_state=42
)
# 数据集 2:非线性可分(环状分布)
X2, y2 = make_circles(
n_samples=500, factor=0.4, noise=0.15, random_state=42
)
# 在两个数据集上执行实验
experiment_on_dataset(X1, y1, name='线性可分数据集')
experiment_on_dataset(X2, y2, name='非线性可分数据集')
实验结果(上传实验结果截图或者简单文字描述)
![图片[1] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebad128d7.png)
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebb68a718.png)
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebbfc647a.png)
![图片[4] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebc91e643.png)
![图片[5] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebd0b413d.png)
![图片[6] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebd9c5f27.png)
![图片[7] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebe2987c8.png)
![图片[8] - AI科研 编程 读书笔记 - 【人工智能】【Python】支持向量机(SVM)实验 - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/06/6819ebeb086d1.png)
D:\AnacondaEnvs\PyTorch\python.exe D:\桌面\编程相关\04_IDE练习项目\sklearn\scikit-learn\Lab\lab04.py
数据集:线性可分数据集
– 样本数量:500
– 特征数量:2
– 类别分布:{0: 250, 1: 250}数据集:线性可分数据集(SMOTE过采样之后)
– 样本数量:350
– 特征数量:2
– 类别分布:{0: 175, 1: 175}=== linear 核 SVM ===
最佳参数:{‘C’: 0.1}
测试集准确率:1.0000
混淆矩阵:
[[75 0]
[ 0 75]]
分类报告:
precision recall f1-score support0 1.00 1.00 1.00 75
1 1.00 1.00 1.00 75accuracy 1.00 150
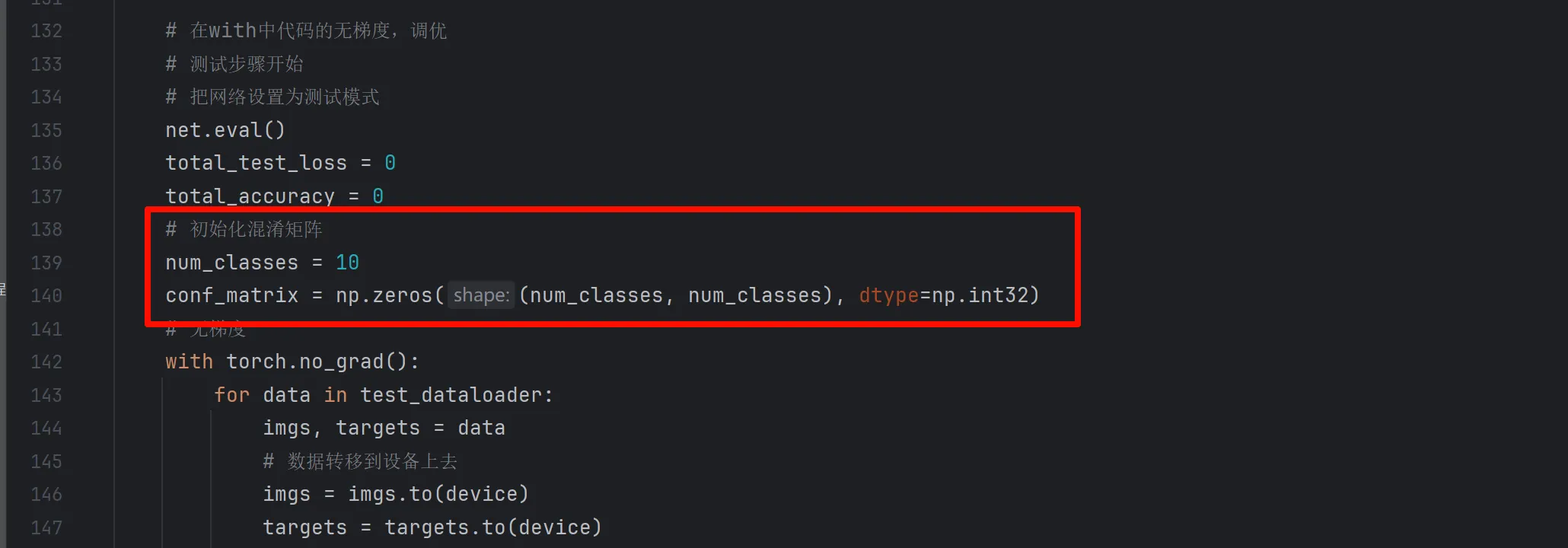
macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150=== poly 核 SVM ===
最佳参数:{‘C’: 0.1, ‘gamma’: ‘scale’}
测试集准确率:1.0000
混淆矩阵:
[[75 0]
[ 0 75]]
分类报告:
precision recall f1-score support0 1.00 1.00 1.00 75
1 1.00 1.00 1.00 75accuracy 1.00 150
macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150=== rbf 核 SVM ===
最佳参数:{‘C’: 0.1, ‘gamma’: ‘scale’}
测试集准确率:1.0000
混淆矩阵:
[[75 0]
[ 0 75]]
分类报告:
precision recall f1-score support0 1.00 1.00 1.00 75
1 1.00 1.00 1.00 75accuracy 1.00 150
macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150数据集:非线性可分数据集
– 样本数量:500
– 特征数量:2
– 类别分布:{0: 250, 1: 250}数据集:非线性可分数据集(SMOTE过采样之后)
– 样本数量:350
– 特征数量:2
– 类别分布:{0: 175, 1: 175}=== linear 核 SVM ===
最佳参数:{‘C’: 0.1}
测试集准确率:0.6133
混淆矩阵:
[[25 50]
[ 8 67]]
分类报告:
precision recall f1-score support0 0.76 0.33 0.46 75
1 0.57 0.89 0.70 75accuracy 0.61 150
macro avg 0.67 0.61 0.58 150
weighted avg 0.67 0.61 0.58 150=== poly 核 SVM ===
最佳参数:{‘C’: 10, ‘gamma’: ‘scale’}
测试集准确率:0.6200
混淆矩阵:
[[18 57]
[ 0 75]]
分类报告:
precision recall f1-score support0 1.00 0.24 0.39 75
1 0.57 1.00 0.72 75accuracy 0.62 150
macro avg 0.78 0.62 0.56 150
weighted avg 0.78 0.62 0.56 150=== rbf 核 SVM ===
最佳参数:{‘C’: 1, ‘gamma’: ‘scale’}
测试集准确率:0.9600
混淆矩阵:
[[73 2]
[ 4 71]]
分类报告:
precision recall f1-score support0 0.95 0.97 0.96 75
1 0.97 0.95 0.96 75accuracy 0.96 150
macro avg 0.96 0.96 0.96 150
weighted avg 0.96 0.96 0.96 150进程已结束,退出代码为 0
在线性可分数据集上,三种核函数的SVM模型表现都非常理想,无论是线性核、多项式核还是RBF核,其在测试集上的准确率均达到了100%。从混淆矩阵来看,模型能够完全正确地分类两类样本,没有产生任何误判或漏判。这说明在数据本身结构线性可分的前提下,SVM即便采用非线性核函数,也能实现优秀的分类性能。在这一过程中,我更倾向于选择线性核作为首选,因为它计算复杂度低,训练时间短,在无需过度建模的情境下能取得同样完美的效果。
然而,当我将模型应用于非线性可分的数据集时,三种核函数的性能表现出现了显著差异。线性核的SVM在该数据集上的准确率仅为61.33%,从混淆矩阵可以看出,模型几乎无法识别类别为0的样本,图中也可以看出,仅正确分类了其中三分之一左右,说明线性核已明显不再适用。我一开始还抱有侥幸心理,以为SVM即便采用线性核也能勉强应对部分非线性任务,但实验结果让我认识到,这种期待在面对明显非线性结构时几乎是不现实的。
多项式核稍微好一些,准确率略有提升(62.00%),但表现依然不理想,特别是在类别为0的识别上,召回率甚至低至0.24,说明该核函数并未有效捕捉数据的非线性特征。而在RBF核的实验中,我看到了截然不同的结果:准确率高达96%,模型在两个类别上的precision和recall都接近完美,这表明了RBF核确实能够很好地拟合非线性边界,使得模型在复杂分布下依旧具备出色的判别能力。
疑难小结(总结个人在实验中遇到的问题或者心得体会)
在本次实验过程中,我遇到了一些经典的问题,也有不少有价值的心得体会。
最初在处理线性可分数据集时,三种核函数的SVM模型都取得了100%的准确率,这让我一开始误以为核函数的选择或许影响不大。然而随着实验深入,我逐渐意识到,这种高性能只是因为数据本身结构简单,对于复杂数据场景并不具有代表性。这让我开始反思模型选择应立足于数据本质,而不是一味追求复杂性。比如在这种情况下,我更倾向于使用线性核,这样的话又能保证准确率,又能节省计算资源。
而在针对非线性可分数据集实验中,我遇到了最大的问题是模型效果差异比较大。线性核的表现和我想的一样,就如绘制的图象一样,超平面直接将环形的不同类别样本“一刀切”,准确率只有61.33%,并且几乎无法识别类别为0的样本。而多项式核虽然理论上能拟合非线性边界,但实际效果还是不理想,让我深刻体会到参数选择的重要性和调参的挑战。相比之下,RBF核的表现非常好,准确率达到了96%。
这次实验不仅加深了我对SVM模型本身的理解,更让我意识到数据结构、模型选择、参数设置和技术搭配他们之间的关系。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。























暂无评论内容