

插入confusion_matrix_scores函数
第一步是在train.py头部插入confusion_matrix_scores函数,如果没有引入NumPy记得引入:import numpy as np
def confusion_matrix_scores(confusion_matrix):
# 获取类别数量
num_classes = confusion_matrix.shape[0]
# 计算样本总数
total_samples = np.sum(confusion_matrix)
# 存储每个类别的精确率,召回率和F1分数
per_class_values = []
for i in range(num_classes):
# 计算类别 i 的真阳性数(TP)
tp_i = confusion_matrix[i, i]
# 计算类别 i 的精确率(Precision)
col_i_sum = np.sum(confusion_matrix[:, i]) # 计算第 i 列的总和
precision_i = tp_i / col_i_sum if col_i_sum != 0 else 0 # 添加除零检查
# 计算类别 i 的召回率(Recall)
row_i_sum = np.sum(confusion_matrix[i, :]) # 计算第 i 行的总和
recall_i = tp_i / row_i_sum if row_i_sum != 0 else 0 # 添加除零检查
# 计算类别 i 的F1分数
if precision_i + recall_i != 0:
f1_i = 2 * precision_i * recall_i / (precision_i + recall_i)
else:
f1_i = 0
# 将计算结果存储到列表per_class_values中
per_class_values.append((precision_i, recall_i, f1_i))
# 打印类别 i 的各项指标
print(f"类别{i}的精确率:{100*precision_i:.2f}%,召回率:{100*recall_i:.2f}%,F1分数:{100*f1_i:.2f}%")
# 计算总的准确率(Accuracy)
accuracy = np.trace(confusion_matrix) / total_samples # np.trace(confusion_matrix) 返回对角线元素之和,即所有TP的总和
# 将每个类别的精确率、召回率和F1分数解包
precisions, recalls, f1s = zip(*per_class_values)
# 计算微平均(micro-average)的精确率、召回率和F1分数
micro_precision = np.mean(precisions)
micro_recall = np.mean(recalls)
micro_f1 = np.mean(f1s)
print(f"总准确率:{100*accuracy:.2f}%", end=" ")
print(f"总精确率:{100*micro_precision:.2f}%", end=" ")
print(f"总召回率:{100*micro_recall:.2f}%", end=" ")
print(f"总F1分数:{100*micro_f1:.2f}%")开始测试前初始化混淆矩阵
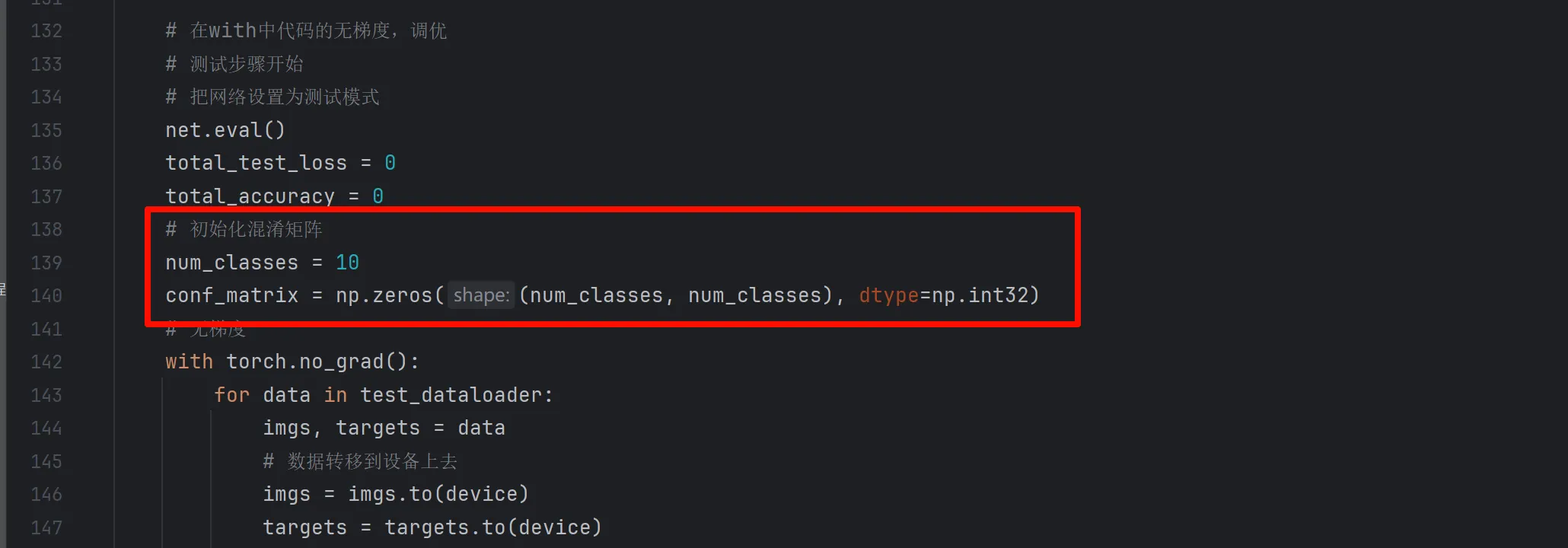
# 初始化混淆矩阵
num_classes = 10
conf_matrix = np.zeros((num_classes, num_classes), dtype=np.int32)计算准确率后更新混淆矩阵
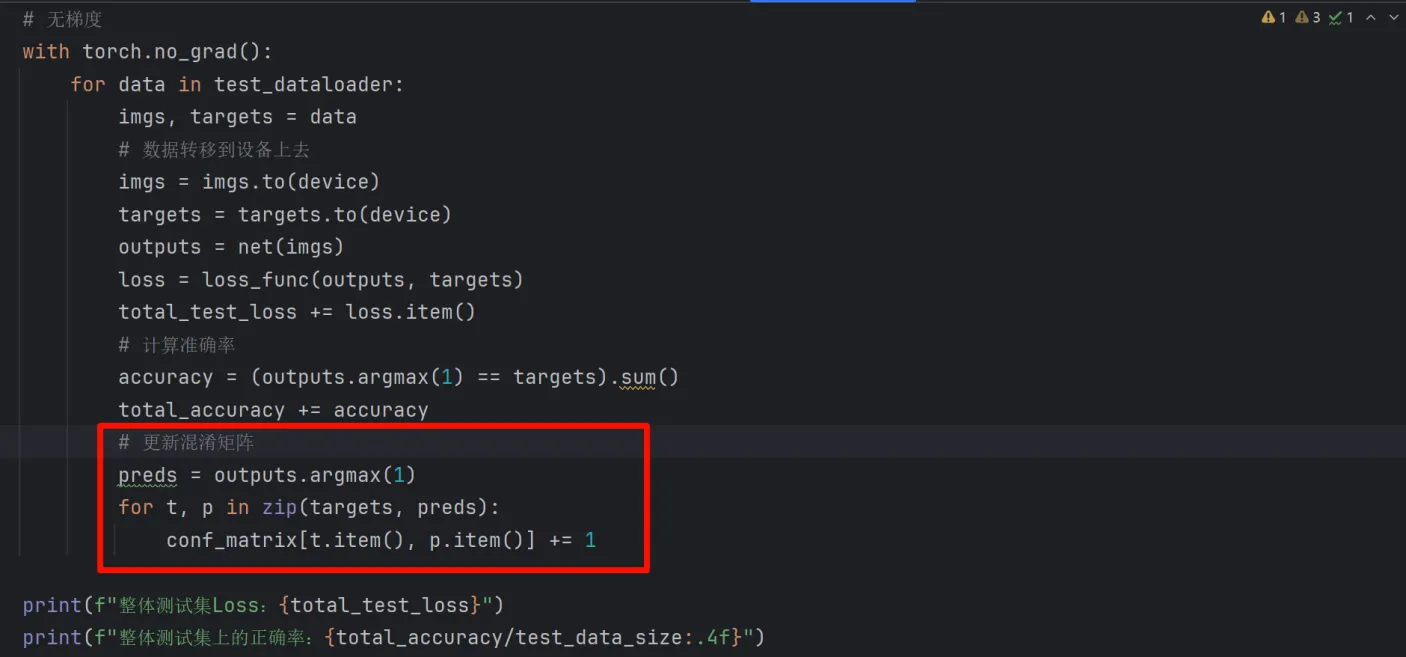
preds = outputs.argmax(1)
for t, p in zip(targets, preds):
conf_matrix[t.item(), p.item()] += 1outputs.argmax(1)用于获取输出的最大预测值(也就是Top-1),output是二维张量:[batch_size, 类别数];preds是一维张量[batch_size],相当于提取出一个类别。
for t, p in zip(targets, preds)是同时遍历targets(真实标签)和真实标签对应的preds(预测标签),然后在conf_matrix的t.item()和p.item()位置更新混淆矩阵,也就是+=1。
打印test acc和loss之后打印混淆矩阵
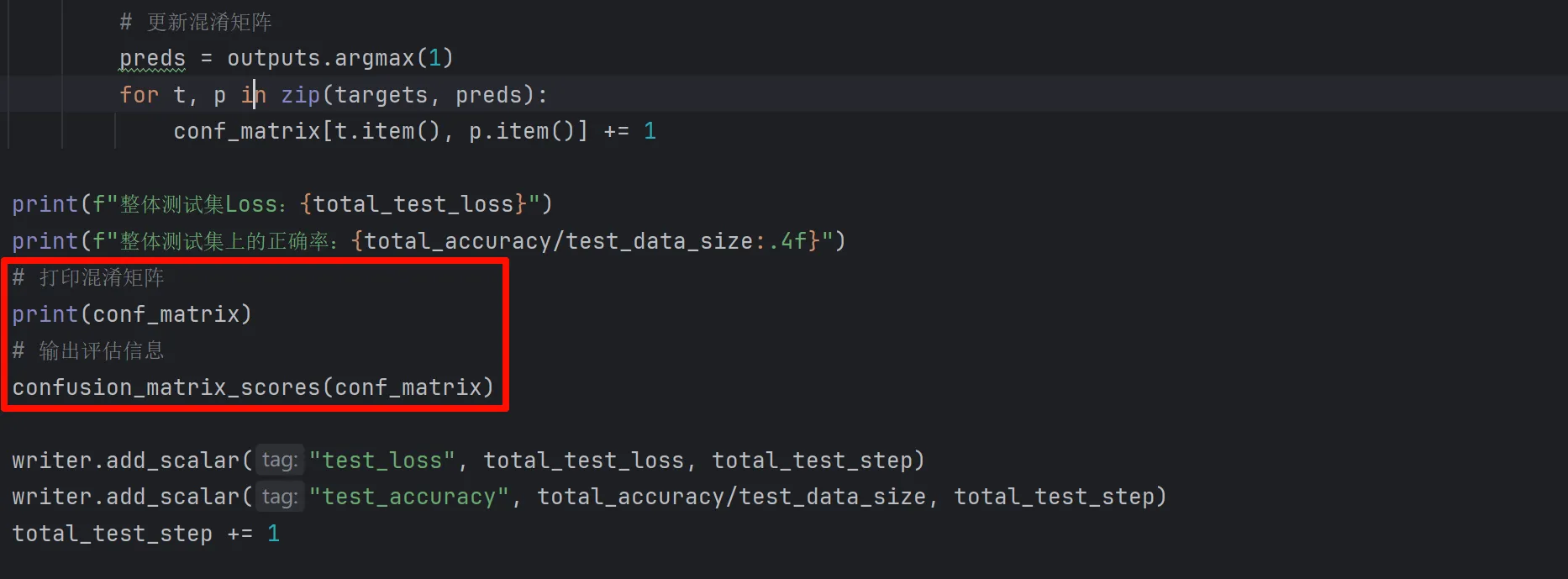
# 打印混淆矩阵
print(conf_matrix)
# 输出评估信息(通过调用confusion_matrix_scores函数)
confusion_matrix_scores(conf_matrix)© 版权声明
1. 除特殊说明外,本网站所有原创文章的版权归作者所有,未经授权,禁止以任何形式(包括但不限于转载、摘编、复制、镜像等)发布至任何平台。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。
THE END

























暂无评论内容