

我使用随机森林、梯度提升和支持向量回归三种算法对音乐流行趋势预测进行了实验。实验采用阿里天池音乐数据集,通过特征工程提取时间特征、滞后特征和艺人静态特征,并进行异常值处理。结果显示随机森林和梯度提升表现优异(测试集R² 0.97),而SVR效果较差(R² 0.81)。我发现特征工程和异常值处理对模型性能提升至关重要,其中1日和7日播放量滞后特征最具预测力。
描述算法、数据集、及所设计的实验方案
数据集介绍
本次实验使用阿里天池平台的音乐流行趋势预测数据集:
https://tianchi.aliyun.com/dataset/137324
网页中有俩文件如下
- 用户行为数据(mars_tianchi_user_actions.csv)
数据量:约1588万条记录。
核心字段:用户ID、歌曲ID、行为时间戳、行为类型(1代表播放,2是下载,3是收藏)、还有对应的日期。
数据质量:无缺失值。 - 歌曲元数据(mars_tianchi_songs.csv)
数据量:约2.7万首歌曲信息。
核心字段:歌曲ID、艺人ID、发布时间、初始播放量、歌曲语言、艺人性别。
数据质量:无缺失值和重复行,语言和性别缺失值预处理填充为’Unknown’。
数据划分与预处理
历史数据(2015年3月1日-8月30日,共183天)划分为:
训练集:128天(2015.3.1-7.6)
验证集:36天(2015.7.7-8.11)
测试集:19天(2015.8.12-8.30)
预处理步骤包括
合并用户行为与歌曲元数据,筛选播放行为(action_type=1)。
计算艺人每日总播放量(daily_plays),填充缺失日期为0。
提取时间特征(周几、月份等)、滞后特征(前1/7/30天播放量)、滚动统计特征(均值)、艺人静态特征(歌曲数量、平均初始播放量等)。
对目标变量daily_plays进行IQR异常值处理。
模型方法
采用三种经典机器学习回归算法:
- 随机森林回归(RandomForestRegressor)
集成学习方法,通过多棵决策树平均预测结果,可处理高维数据并提供特征重要性。 - 梯度提升回归(GradientBoostingRegressor)
迭代构建模型,每棵树纠正前序模型残差,预测精度高,适合结构化数据。 - 支持向量回归(SVR)
基于支持向量机的回归扩展,通过寻找最优函数拟合数据,适合高维和非线性关系,但大规模数据耗时较长。
实验流程与优化
数据预处理流程:我用了ColumnTransformer整合标准化和独热编码(OneHotEncoder),只在训练集拟合避免数据泄露。
超参数调优:通过网格搜索结合K折交叉验证优化了模型参数,调优的时候评估指标是均方误差(MSE)。
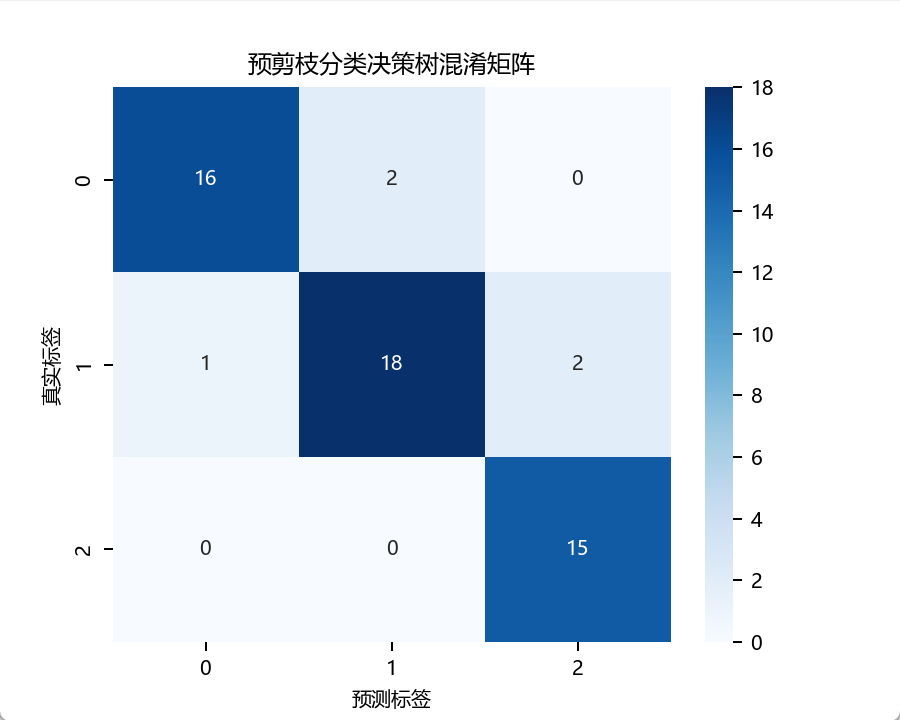
模型评估:我在验证集和测试集上使用MSE、R²分数、平均绝对误差(MAE)评估了性能,通过特征重要性、预测值与实际值对比、残差分析等验证模型的表现。
实验详细操作步骤或程序清单
实验结果(上传实验结果截图或者简单文字描述)
Matplotlib图像展示
![图片[1] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682eccb5dffa6.png)
![图片[2] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682eccdd876ab.png)
![图片[3] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682ecceaa66eb.png)
![图片[4] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682eccf8d6a52.png)
![图片[5] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682ecd077b245.png)
![图片[6] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682ecd1490ebc.png)
![图片[7] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682ecd28f3a18.png)
![图片[8] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682ecd380f465.png)
![图片[9] - AI科研 编程 读书笔记 - 【人工智能】【Python】综合算法实验(随机森林、梯度提升、支持向量回归解决音乐流行趋势预测任务) - AI科研 编程 读书笔记 - 小竹の笔记本](https://img.smallbamboo.cn/i/2025/05/22/682ecd48ecef0.png)
控制台输出
下面是整个控制台的输出
D:\AnacondaEnvs\PyTorch\python.exe D:\桌面\编程相关\04_IDE练习项目\sklearn\Sklearn-Last\main3.py
历史数据总天数: 183
训练集天数: 128, 日期: 20150301 – 20150706
验证集天数: 36, 日期: 20150707 – 20150811
测试集天数: 19, 日期: 20150812 – 20150830— 2.3 数据探索 —
— (1) 数据质量分析 —— actions_df 数据质量 —
actions_df 信息:
RangeIndex: 15884087 entries, 0 to 15884086
Data columns (total 5 columns):
# Column Dtype
— —— —–
0 user_id object
1 song_id object
2 gmt_create int64
3 action_type int64
4 Ds int64
dtypes: int64(3), object(2)
memory usage: 605.9+ MB缺失值分析 (actions_df):
user_id 0
song_id 0
gmt_create 0
action_type 0
Ds 0
dtype: int64重复行数量 (actions_df): 2738252
— songs_df 数据质量 —
songs_df 信息:
RangeIndex: 26958 entries, 0 to 26957
Data columns (total 6 columns):
# Column Non-Null Count Dtype
— —— ————– —–
0 song_id 26958 non-null object
1 artist_id 26958 non-null object
2 publish_time 26958 non-null int64
3 song_init_plays 26958 non-null int64
4 Language 26958 non-null int64
5 Gender 26958 non-null int64
dtypes: int64(4), object(2)
memory usage: 1.2+ MB缺失值分析 (songs_df):
song_id 0
artist_id 0
publish_time 0
song_init_plays 0
Language 0
Gender 0
dtype: int64songs_df 缺失值处理后:
song_id 0
artist_id 0
publish_time 0
song_init_plays 0
Language 0
Gender 0
dtype: int64重复行数量 (songs_df): 0
— 数据预处理 —
— (2) 数据分布可视化分析 —
— 2.4 特征工程 —
聚合艺人歌曲信息 (包括分类特征)…艺人主要性别在独热编码前的唯一值和计数:
main_gender
2 46
1 30
3 24
Name: count, dtype: int64
正在创建每日特征…
每日特征创建完成 (分类特征待后续处理)。— 对 daily_plays 进行异常值处理 (IQR Capping) —
daily_plays IQR: 下限: -903.0, 上限: 1865.0
daily_plays 处理后描述:
count 18300.000000
mean 575.105355
std 586.185059
min 0.000000
25% 135.000000
50% 317.000000
75% 827.000000
max 1865.000000
Name: daily_plays, dtype: float64
— 特征分布图绘制 (创建后) —— (3) 特征相关性检验 —
— 2.5 模型构建 —
— (1) 划分训练集/验证集/测试集 —
训练集样本数: 9800, 特征数: 21
验证集样本数: 3600
测试集样本数: 1900— 模型训练、调优与评估 —
— RandomForest —
Fitting 3 folds for each of 8 candidates, totalling 24 fits
网格搜索完成,耗时: 15.79 秒
最优参数: {‘max_depth’: 10, ‘min_samples_split’: 5, ‘n_estimators’: 50}
最优交叉验证分数 (MSE): 8294.37758991697
验证集 MSE: 8442.02, R2: 0.98
测试集 MSE: 11497.52, R2: 0.97, MAE: 54.22— GradientBoosting —
Fitting 3 folds for each of 8 candidates, totalling 24 fits
网格搜索完成,耗时: 11.26 秒
最优参数: {‘learning_rate’: 0.05, ‘max_depth’: 5, ‘n_estimators’: 100}
最优交叉验证分数 (MSE): 8301.515011153782
验证集 MSE: 8357.09, R2: 0.98
测试集 MSE: 10886.99, R2: 0.97, MAE: 54.04— SVR —
Fitting 3 folds for each of 6 candidates, totalling 18 fits
网格搜索完成,耗时: 9.67 秒
最优参数: {‘C’: 10, ‘gamma’: ‘auto’, ‘kernel’: ‘rbf’}
最优交叉验证分数 (MSE): 15546.098127690211
验证集 MSE: 28070.88, R2: 0.92
测试集 MSE: 70172.55, R2: 0.81, MAE: 224.40— 2.6 模型验证 —
— 特征重要性 (随机森林) —
— 测试集:预测值 vs 实际值 (所有模型) —
— 残差图 (Residual Plot) —
— 绘制学习曲线 (RandomForest) —
所有分析和评估完成。
进程已结束,退出代码为 0
算法分析
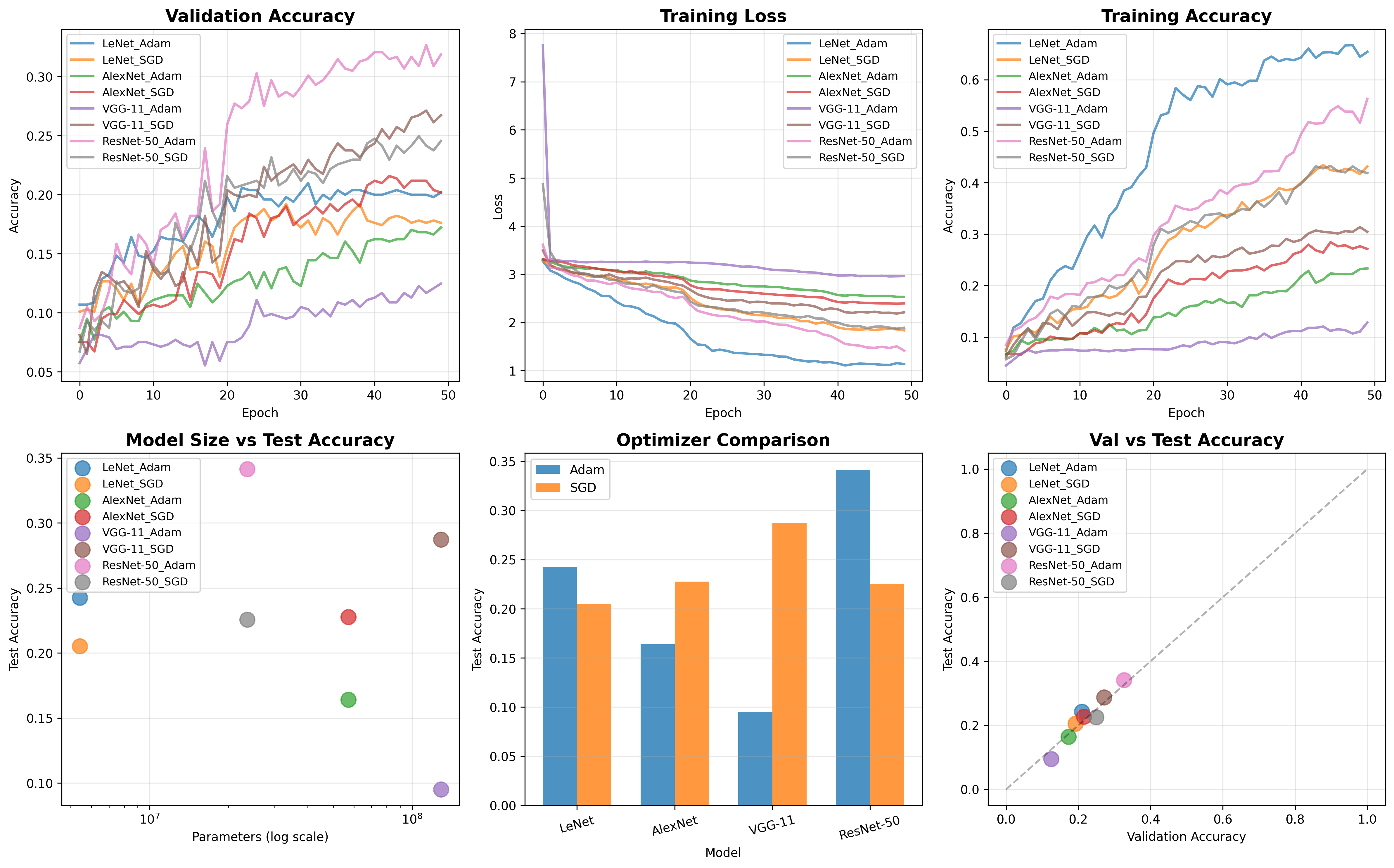
通过分析控制台输出可以看到最终的模型性能如下
集成算法表现很好
随机森林与梯度提升回归在验证集和测试集上表现接近,验证集 MSE 约 8300-8400,R² 达 0.98;测试集 MSE 约 10800-11500,R² 0.97,MAE 约 54。两者通过网格搜索优化参数后,泛化能力稳定,适合处理高维结构化数据,且特征重要性可解释性强。
支持向量回归(SVR)的效果较差
测试集 MSE 高达 70172,R² 仅 0.81,MAE 224,表明 SVR 在大规模数据中效率低,非线性拟合能力不足,可能因核函数选择或计算复杂度限制,不适用于该任务。
网格搜索结果如下
随机森林回归:最优参数为 {‘max_depth’: 10,’min_samples_split’: 5, ‘n_estimators’: 50},最优交叉验证分数(MSE)为 8294.37758991697,验证集 MSE 为 8442.02,R² 为 0.98,测试集 MSE 为 11497.52,R² 为 0.97,MAE 为 54.22。
梯度提升回归:最优参数为 {‘learning_rate’: 0.05,’max_depth’: 5, ‘n_estimators’: 100},最优交叉验证分数(MSE)为 8301.515011153782,验证集 MSE 为 8357.09,R² 为 0.98,测试集 MSE 为 10886.99,R² 为 0.97,MAE 为 54.04。
支持向量回归:最优参数为 {‘C’: 10, ‘gamma’: ‘auto’, ‘kernel’: ‘rbf’},最优交叉验证分数(MSE)为 15546.098127690211,验证集 MSE 为 28070.88,R² 为 0.92,测试集 MSE 为 70172.55,R² 为 0.81,MAE 为 224.40。
结果分析
随机森林回归和梯度提升回归在验证集和测试集上的表现比较为接近,且均优于支持向量回归。随机森林回归和梯度提升回归的 MSE 较低,R² 较高,说明它们能够较好地拟合数据,并且具有较好的泛化能力。支持向量回归的 MSE 较高,R² 较低,说明它在处理大规模数据时效率较低,并且非线性拟合能力不足。
通过网格搜索结合 K 折交叉验证,有效地优化了模型的参数,提高了模型的性能。
提取的时间特征、滞后特征、滚动统计特征和艺人静态特征等对模型的性能有重要影响。通过对特征进行标准化和独热编码处理,提高了模型的收敛速度和泛化能力。
疑难小结(总结个人在实验中遇到的问题或者心得体会)
一开始,我最大的体会就是特征工程的重要性。在最初尝试的时候,我下载了数据集,直接用一些原始特征就去训练模型,结果模型的表现非常不理想。我想了想是因为特征数量太少,没什么代表性。发现到这个问题后,我投入了大量精力去整合现有特征并创建新的衍生特征,比如艺人过去几天的播放量、滚动平均播放量,以及艺人本身的属性(歌曲数量、平均初始播放量、语言、性别)。这些特征的加入,极大地丰富了数据的信息维度,为模型提供了更全面的视角去理解艺人播放量的动态变化。
一开始,我直接拿了随机森林来调参,虽然R2能达到0.95,看起来还是不错的,但我感觉这个MSE有点大,模型的预测精度可能还有提升空间。这时候,我就开始思考是不是数据本身的问题,尤其是那些极端异常值,因为我在数据分布图中看到了很多距离很远的点。
在咨询了老师之后,我决定将重点放在处理艺人每日播放量的异常值上。我采用了IQRCapping的方法,把那些播放量特别高或者特别低的异常值限制在合理的范围内。这个改动效果非常显著,处理完异常值后,模型的R2进一步优化到了0.97,同时MSE也得到明显的降低。数据清洗和异常值处理不仅仅是“表面工作”,它们对模型的最终性能有着决定性的影响,甚至比单纯地更换更复杂的模型或更深入的调参更为关键。
这次实验让我更加确信了数据预处理和特征工程是机器学习项目成功的基石。虽然机器学习中貌似算法模型是核心,但高质量的特征和干净的数据也很重要。同时,遇到问题时主动寻求帮助、思考,然后从不同视角审视数据,往往能带来意想不到的突破。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。























暂无评论内容