

ViT:一幅图像等于16×16个词:用于大规模图像识别的Transformer

谷歌学术引用量:40628。这篇论文主要探讨的是Transformer模型在图像分类领域的应用。
作者团队来自于Google Research, Brain Team(谷歌公司的研究部门,Brain Team即谷歌大脑团队,关注机器智能方面)。论文最初在2020年10月发布在arXiv上,Published as a conference paper at ICLR 2021。ICLR是机器学习和深度学习领域的顶级会议之一。
“An Image is Worth 16×16 Words” 可以理解为 “一幅图像等于16×16个词”,这里指的是将图像划分为16×16大小的块(patches),每个块作为一个“词”来处理。
“Transformers for Image Recognition at Scale” 意味着 “用于大规模图像识别的Transformer”,强调Transformer模型在处理大规模图像识别任务中的应用。
动机
语义分割在实际应用中非常重要,如土地覆盖图绘制、城市变化检测、环境保护和经济评估等。
卷积神经网络(CNN)由于其强大的局部信息提取能力,在语义分割中占主导地位,但其固定的感受野限制了网络捕获全局上下文的能力。
Transformer由于其在全局信息建模方面的巨大潜力,尤其在图像分类、目标检测和语义分割等计算机视觉任务中表现出色。
创新点
图像切块:将输入图像划分为固定大小的块(如16×16),然后将每个块展平并通过线性变换映射到固定维度。
位置嵌入:给每个图像块添加位置嵌入,以保留图像块之间的位置关系。
Transformer编码器:将处理后的图像块序列输入到标准的Transformer编码器中,通过多头自注意力机制和前馈神经网络进行处理。
分类标记:在图像块序列前添加一个可学习的分类标记,通过Transformer编码器后,该标记的输出用于最终的图像分类。
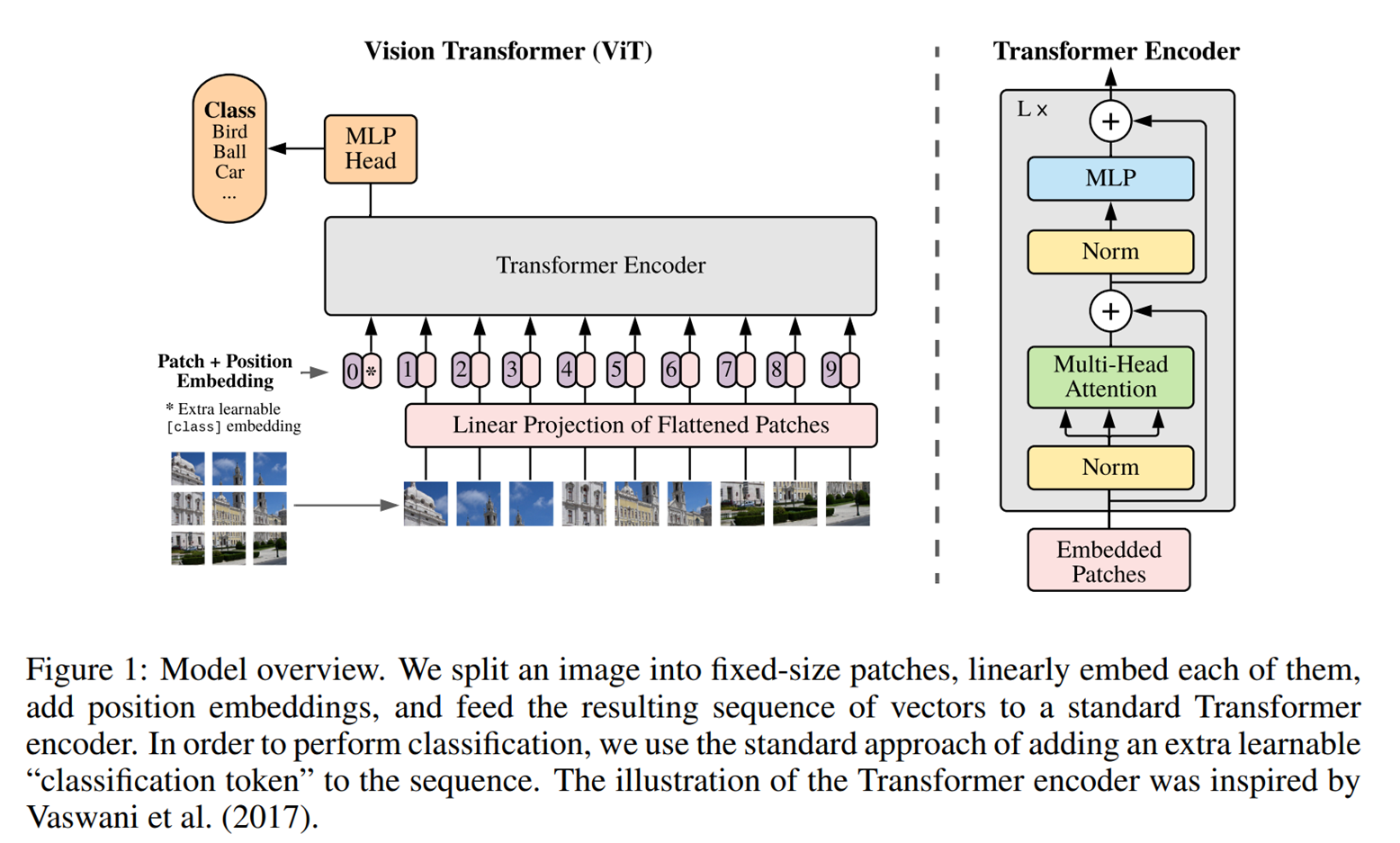
模型结构
1.图像划分为固定大小的块(**patches)**:输入图像被划分为固定大小的块(如16×16像素)。每个块被展平(flattened)成一个一维向量。
2.线性投影(**Linear Projection)**:将每个展平的块通过一个线性变换(线性投影)映射到固定的维度,生成嵌入向量。在这个过程中,每个块的维度被转换为与Transformer输入的维度相匹配的向量。
3.位置嵌入(**Position Embedding)**:为每个块添加位置嵌入(位置编码),以保留块之间的位置关系。这些位置嵌入是可学习的。
4.分类标记(**Classification Token)**:在所有块的序列前添加一个额外的可学习的分类标记([class] token)。这个标记的最终输出将用于分类任务。
5.Transformer**编码器(Transformer Encoder)**:所有块的嵌入向量序列连同分类标记一起被输入到标准的Transformer编码器中。Transformer编码器包含多层(L层)标准的Transformer块,每个块由多头自注意力机制(Multi-Head Attention)和前馈神经网络(MLP)组成。每层Transformer块中都有归一化层(Norm)和残差连接(Residual Connections)。
6.分类头(**MLP Head)**:分类标记的输出经过一个多层感知机(MLP)分类头,生成最终的分类结果。
步骤
1.图像切块:图像被划分为一组固定大小的块,每个块展平并通过线性投影映射到固定维度。每个块再加上位置嵌入,以保留其在原始图像中的位置信息。
2.Transformer**编码器**:加上分类标记的嵌入向量序列被输入到Transformer编码器中。编码器通过多个自注意力和前馈神经网络层进行处理,捕捉块之间的全局依赖关系。
3.分类输出:分类标记的输出经过分类头生成最终的分类结果。
实验结果
在ImageNet-21k和JFT-300M数据集上预训练的ViT模型,在多个图像识别基准测试(如ImageNet、CIFAR-100、VTAB等)上取得了优秀的结果。最佳模型在ImageNet上达到了88.55%的准确率,在CIFAR-100上达到了94.55%的准确率,在VTAB的19个任务上达到了77.63%的平均准确率。相比于同等规模的CNN,ViT在预训练阶段需要的计算资源更少。
对比算法
ResNet:作为主流的CNN架构,与ViT在相同数据集和任务上进行对比。
混合模型:结合CNN和Transformer的特性,将CNN的特征图作为Transformer的输入序列。
其他注意力机制模型:使用局部注意力、稀疏注意力等方式实现的模型。
数据集
预训练数据集
ImageNet-21k:21k类,共14M张图像。JFT-300M:18k类,共303M张高分辨率图像。
评估数据集
ImageNet及其ReaL标签集。CIFAR-10/100。Oxford-IIIT Pets。Oxford Flowers-102。
VTAB:包含19个分类任务的套件,涉及自然图像、专业图像和结构化图像。
改进空间
位置嵌入优化:探索更先进的二维位置嵌入方式,可能进一步提升性能。
自监督学习:虽然论文中进行了少量自监督学习的实验,但未来在这方面仍有很大潜力。
更大的模型和数据集:随着硬件和数据集规模的增加,训练更大的ViT模型可能会进一步提升性能。
混合架构优化:继续优化CNN和Transformer结合的混合模型,以充分利用两者的优势。
Swin Transformer:使用滑动窗口的分层视觉Transformer

谷歌学术引用量:20049。
2021年发布于ICCV 2021(国际计算机视觉会议)
作者团队:微软亚洲研究院、中国科学技术大学、西安交通大学和清华大学。
动机
现有的Vision Transformer (ViT) 模型虽然在图像分类任务中表现出色,但在处理高分辨率图像或密集视觉任务时效率较低,且性能不佳。论文的目标是设计一种新的Transformer架构,既能处理高分辨率图像,又能在多种视觉任务中表现出色。
创新点
滑动窗口自注意力机制
通过在连续的自注意力层之间移动窗口,使得每个窗口的查询块共享相同的键集合,从而提高计算效率,防止小窗口之间独立计算,会损失掉很多信息。
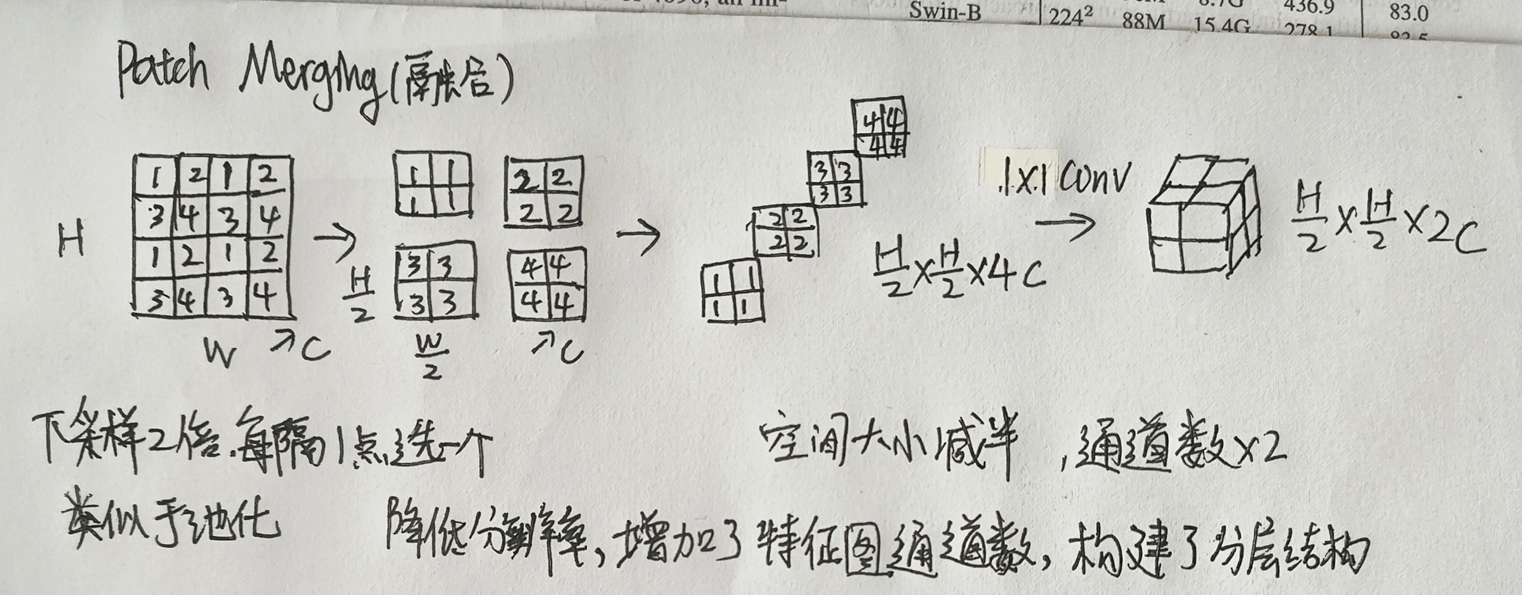
层次化特征表示
通过将输入图像分割成非重叠的块,并在每个块上应用线性嵌入,然后在多个Transformer块中进行特征变换,并逐步合并块以减少token数量,最终形成层次化的特征表示。
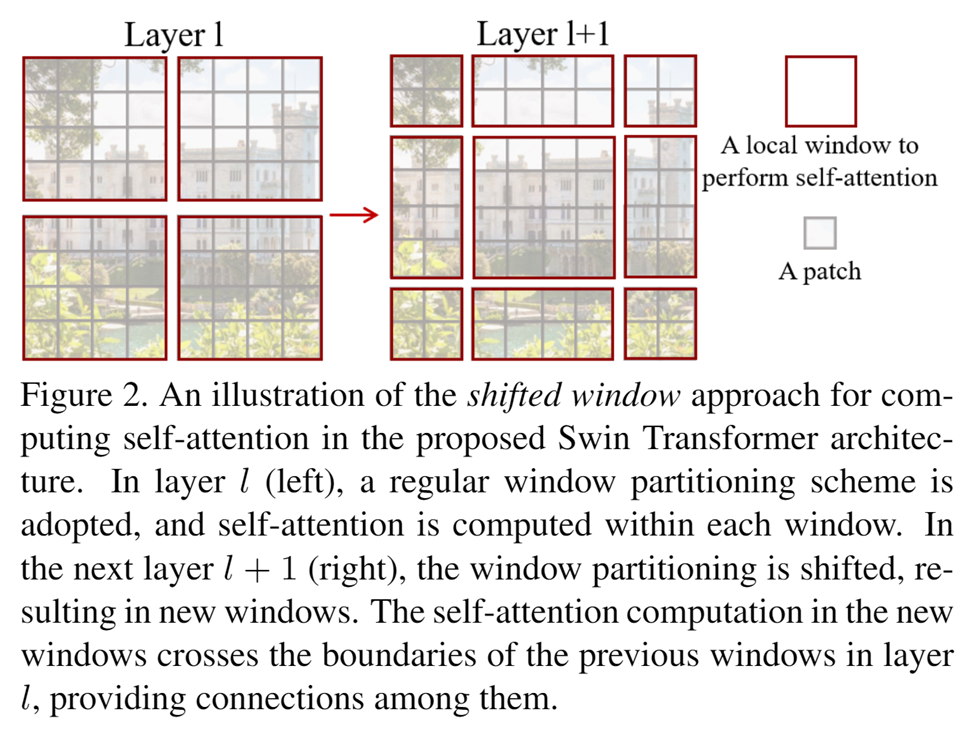
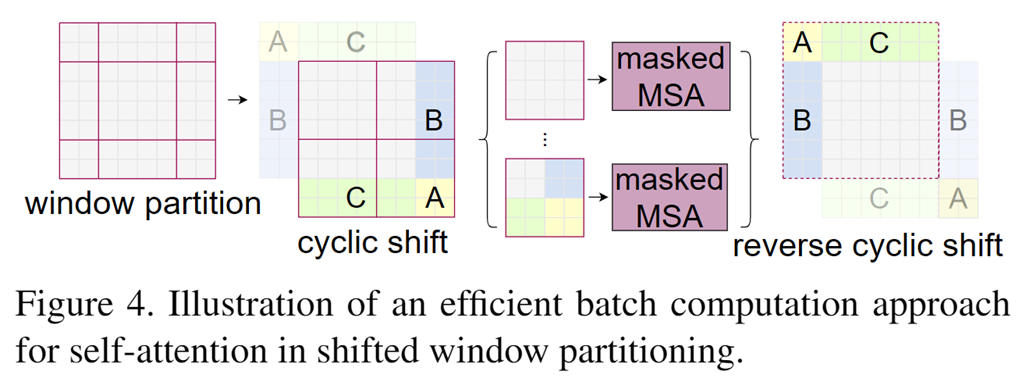
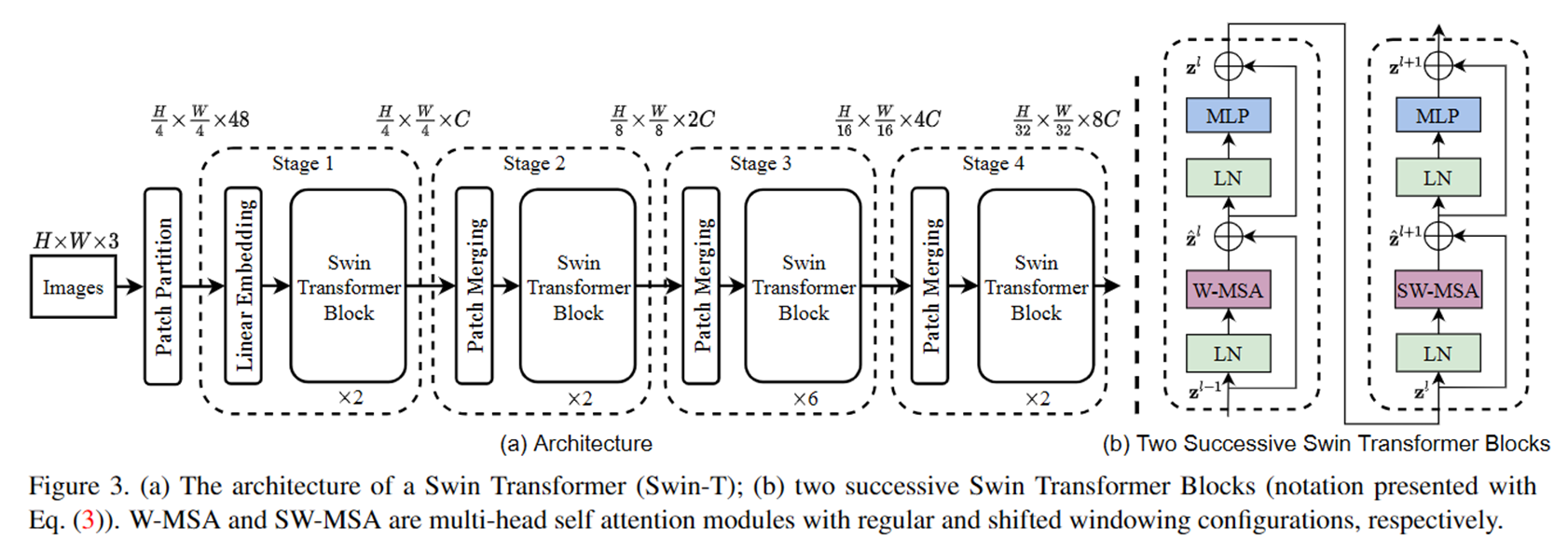

实验结果
在ImageNet-1K图像分类任务中,Swin Transformer显著优于之前的ViT和ResNet模型,取得了87.3%的Top-1准确率。
在COCO目标检测任务中,Swin Transformer达到了58.7的box AP和51.1的mask AP,比之前的最优方法分别提高了2.7和2.6。
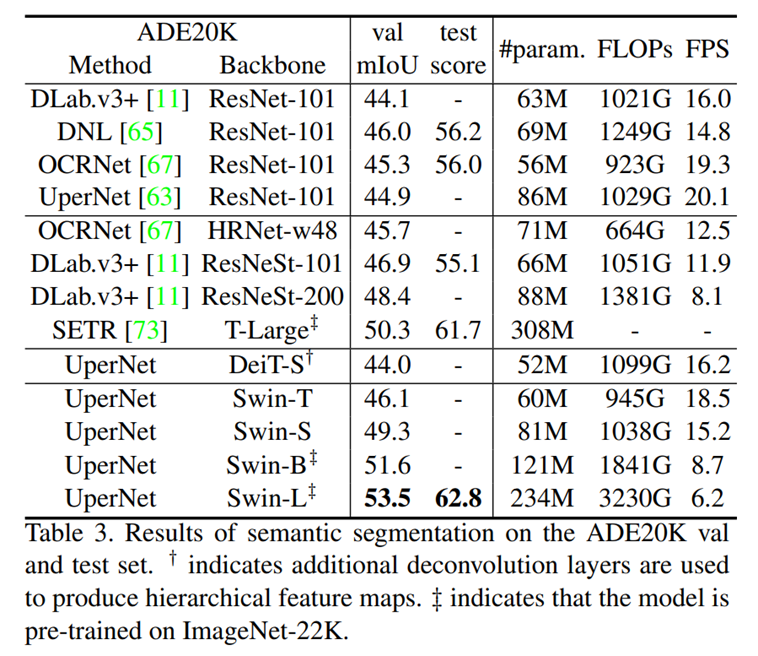
在ADE20K语义分割任务中,Swin Transformer取得了53.5的mIoU,比之前的最优方法高出3.2。
对比算法
与多种最新的Transformer架构(如ViT、DeiT、Performer)以及传统的卷积神经网络架构(如ResNet、RegNet)进行对比,结果显示Swin Transformer在速度和准确性之间取得了最佳的平衡。
数据集
ImageNet-1K(图像分类)
COCO(目标检测)
ADE20K(语义分割)
改进空间
尽管Swin Transformer在多个视觉任务中表现出色,但其架构是从标准Transformer手动改编而来,仍有进一步改进的潜力。例如,可以通过更深入的架构搜索或结合其他方法来提升性能。
2. 论文总结类文章中涉及的图表、数据等素材,版权归原出版商及论文作者所有,仅为学术交流目的引用;若相关权利人认为存在侵权,请联系本网站删除,联系方式:i@smallbamboo.cn。
3. 违反上述声明者,将依法追究其相关法律责任。






















- 最新
- 最热
只看作者